


Hi all,
I was working through the update to the 2020.2 version of the Xilinx and realized there was a few small awesome things that we have included that might be of interest to the greater community! I also think that you could translate this information into just about any system out there. While I do not use other systems, I would think they have similar features / capabilities as I am going to discuss.
In this blog, I want to talk about tweaking performance in Vivado. Aside from building CLANG, OPENCV, and CHROMIUM for PetaLinux on the Ultra96V2, the PL binary generally has some of the longest single build times for a system. Consider the complexities of fabricating a new chip at each build! I think we can appreciate that larger chips just take longer to produce an image.
Certainly there are many things that you can do to help speed things up. Things such as
- islanding logic
- locking down partial designs
- maintaining proper and reasonable constraints
- ensuring you use a proper and efficient flow for your data and busses
- pinning out to minimize routing
- maintaining proper alignment with clock trees / regions
- leveraging hardware acceleration (DSPs, VCU, memory controllers, SERDES elements, AI-Cores, NOC and more)
One of the things that the PetaLinux build flow does well is efficiently use system resources while building. It is the nature of software to create object files. These files can certainly be created in parallel. So, referring to Amdahl's Law, we can get more work done in less time...to a point! Of course, at some point we lose out, but that's for another article. For the here and now, 8 core, 16 core machines do very well with this! I had even spoke about a similar topic more around the atomicy of problems and how FPGAs are great at bucking Amdahl's Law, back at a Linaro Developers conference a few years ago when meeting people in person was a thing. ;-)
The same holds true for some parts of the BITSTREAM generation for a programmable logic system.
Generally speaking, all PL systems do the same thing:
- define the hardware (setups the goes-intas/goes-outtas, what hardware rules can be followed)
- bring in IP/logic/definitions for clocks, etc.(your problem solving needs! Your request for hardware written in many forms)
- synthesize (turns your request for logic into gates/hardware - a netlist)
- implement (turns the netlist into a piece of hardware that can be placed into the chip)
- generate bitstream (takes the implemented design, creates the binary file that can be programmed INTO the SRAM (or flash) of your chip)
Generally speaking, creating a netlist can be made parallel. The more parallel, the faster the design can be created. There are also other parts which also benefit from parallelism. In Xilinx tools, Implementation also greatly benefits. Keep in mind that claim is very vendor specific. This is especially true around place and routing due to the traditionally very linear "BST" like algorithms of old. We also want to keep to our example of C source to Object files, synthesis is most similar for this article.
In Vivado, everything in the GUI is associated with a corresponding TCL command. This is great for reproducibility (delete a project to start over, paste in all commands, you are back to where you were!), design tracking (normal source controls work on TCL), quick prototyping (snippets can be passed amongst coworkers), easy remote builds (no GUI...no problem!), as well as a host of other reasons. In Vivado, once you are ready to build your bitstream, you can click on Generate Bitstream.

Which will check through to ensure that ALL prior required steps are complete. If not, the tool will coordinate with your desires and build what you want. What is important, once you get to the actual DOING of the build, you will be requested to determine the resources that you want Vivado to use.

As you can see, we can CHOOSE the number of jobs. You can think of this as the number of parallel threads - although not exactly as there are lots of interdependencies and single line decision making that occurs in any build. Consider this feature similar to when you finally weave the object files together to condense them down to the binary for your processor.
For the sake of something real, I ran a test with a script based build for the MicroZed7020, Base Design, 2020.2 Vitis enabled platform XSA.
If I run with jobs = 4, it takes my build machine 5 minutes and 35 seconds
If I run with jobs = 1, it takes my build machine 9 minutes and 30 seconds
As you can see, that one change effected our build quite significantly! The larger your design, the more cores you have access to, the larger your on die cache (reduces accessing slower memory through cache misses), GENERALLY the greater the impact. It is amazing that for some time, we have been in an age where in some cases, the bus bandwidth to your processor on your build machine is the limiting factor. In the past, I have done tests with traditional drives, ram drives, ssd, ssd and traditional arrays in RAID 0, 0/1, 5, mapped network drives, Gigabit + 10G, virtual / direct. Also note that higher clock speeds do not always equal faster builds, just due to the monster size of these projects. For example, in the past I have compared an i5, i7, comparable Xeon processor. 3.7GHz, 3.5GHz, 2.75GHz respectively. For small builds (think equivalent to MiniZed or MicroZed) the i5 was the fastest! For a build similar to the UltraZed-EV, a very large part, the Xeon was the fastest. It had to do with the massive on-die cache the Xeon had. It reduced the waiting time for the processor to actually GET the thing it wanted to build.
I think we can conclude that It is important to maximize the number of jobs that can be run. And if you are using TCL to drive your Vivado, you will use the launch_runs command. This is the equivalent of getting to the above GUI Launch Runs screen.
If you look at UG835, you can see the breakdown of all Vivado TCL commands. launch_runs has the option for -jobs #

If you do not specify this, it defaults to a safe "1 job".

So what did we do here at Avnet? Here, I have access to machines that vary from 4-16 cores. I would want to use the most. I also cannot assume that everyone has 16 cores! Thus, I cannot check in code calling out 16 cores! Poking around online, I found that TCL has many ways to access the number of cores!
Here is a snip from our make.tcl that controls most of the flow for our build process (which helps us at Avnet implement Xilinx UltraFast methodology [see UG1046]).
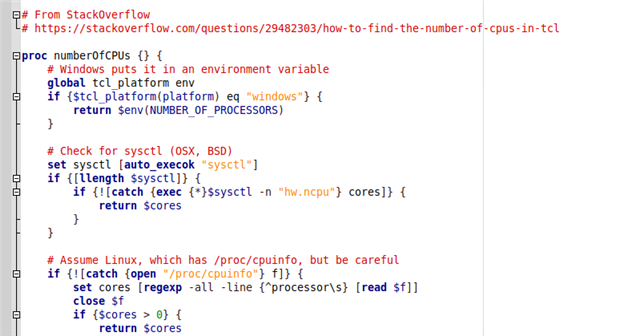
In our MicroZed 7020 example, I only had to modify this one line:

Doing this through TCL, makes this command OS independent (Vivado runs under Windows AND flavors of Linux). This means, I can create support code for our customers, and they and I can run the same builds on any supported machine and the TCL will be smart enough tune it's performance for the machine it is on. This is very similar to the Yocto flow's capabilities used for the PetaLinux build flow.
You can even play games such as leaving 1 processor free so you can still do emails! (modify $numberOfCores with a -1)
Overall, I suggest you do something similar in your build flow! Let the tools do the work for you, they are exceptionally good at repetitive tasks! You can certainly feel free to implement your own custom designs leveraging our build scripting, which is free to use/leverage under the included licenses. We also support this repository through updates and forum posts, as long as it is being used with an Avnet based SOM or SBC, regardless of the carrier/supporting hardware included.
Let me know below if you have any tips / tricks to help more efficiently use your limited CPU cycles!
--Dan
If you have an interest in our Avnet products that can be used to speed your solutions to market:
| Buy Ultra96-V2Buy Ultra96-V2 |
| Buy Ultra96-V2 I-gradeBuy Ultra96-V2 I-grade |
| Buy Ultra96-V2 4A Power SupplyBuy Ultra96-V2 4A Power Supply |
| Buy Ultra96-V2 JTAG/UART PodBuy Ultra96-V2 JTAG/UART Pod |
| Buy UltraZed-EG Starter KitBuy UltraZed-EG Starter Kit |
| Buy UltraZed-EV Starter KitBuy UltraZed-EV Starter Kit |