


Previous Blogs:
Blog #1: CNN HW Accelerator for Handwriting Recognition - HDMI and USB Camera Bring-Up
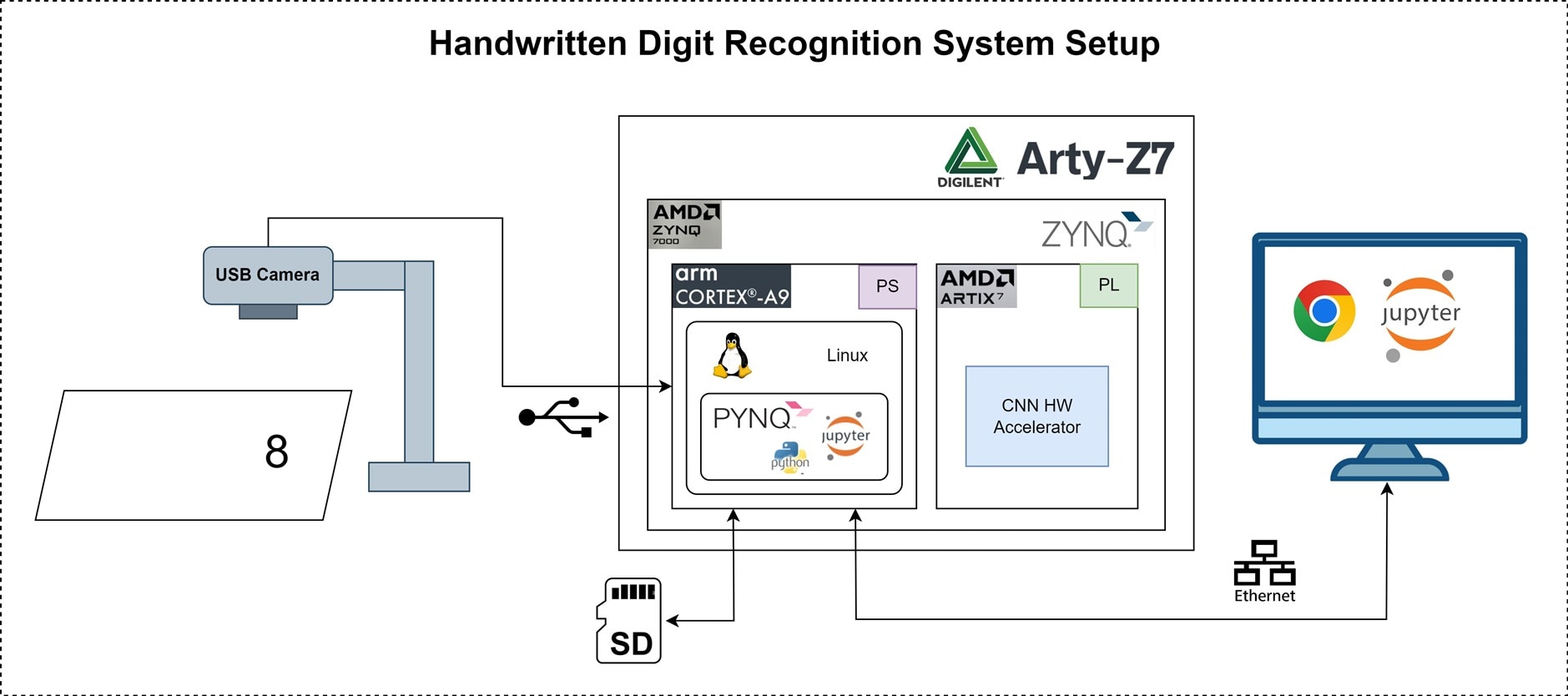
Handwritten Digit Recognition System Setup
This project showcases an innovative and efficient handwritten digit recognition system built for the Element14 Eye on Intelligence Challenge. The system is based on the Digilent Arty Z7, which integrates the AMD Zynq-7000 SoC to combine software programmability with hardware acceleration seamlessly.
System Overview
-
Hardware Platform: Arty Z7
- The Arty Z7 board leverages the powerful Zynq-7000 SoC, which includes:
- PS (Processing System): ARM Cortex-A9 running PYNQ Image.
- PL (Programmable Logic): Custom-built CNN hardware accelerator.
- An SD card is used to boot the system, providing flexibility in deploying the setup.
- The Arty Z7 board leverages the powerful Zynq-7000 SoC, which includes:
-
Custom CNN Hardware Accelerator
- A Convolutional Neural Network (CNN) was implemented in the FPGA fabric (PL) to efficiently process images of handwritten digits. The hardware accelerator is optimized for MNIST digit recognition, ensuring low-latency and high-accuracy classification.
- A Convolutional Neural Network (CNN) was implemented in the FPGA fabric (PL) to efficiently process images of handwritten digits. The hardware accelerator is optimized for MNIST digit recognition, ensuring low-latency and high-accuracy classification.
-
System Workflow
- USB Camera Input: The system captures real-time handwritten digits via a USB camera.
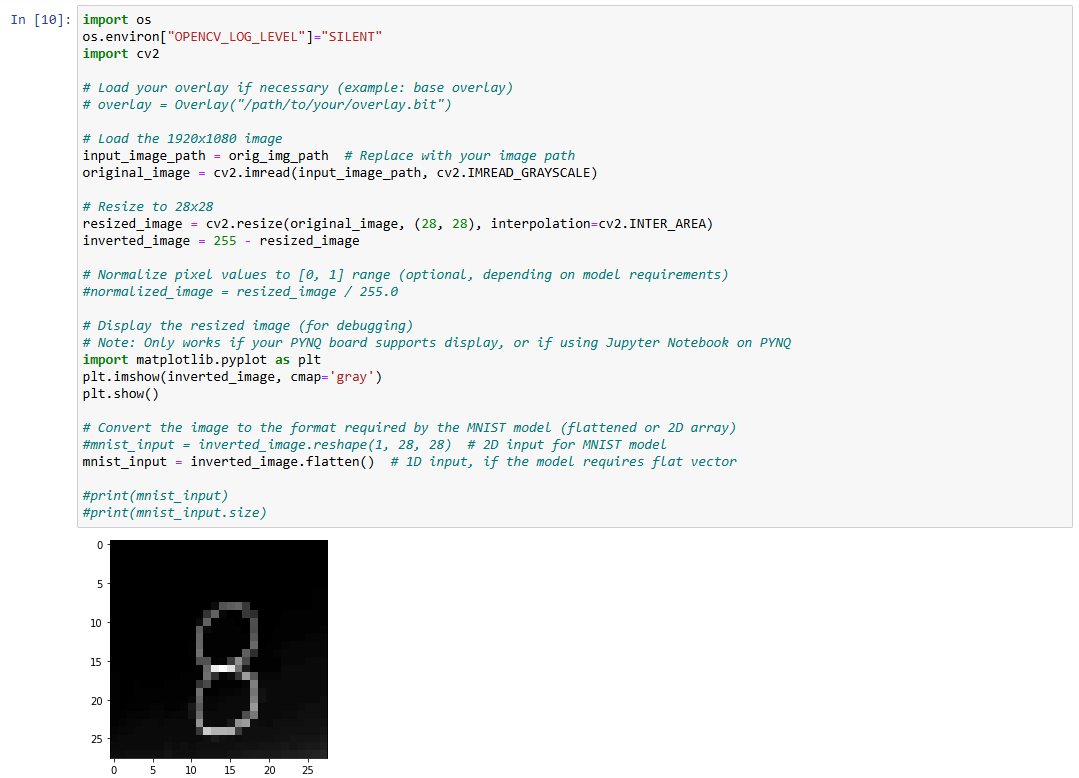
- Preprocessing: The input image is resized and normalized before being fed into the CNN accelerator.
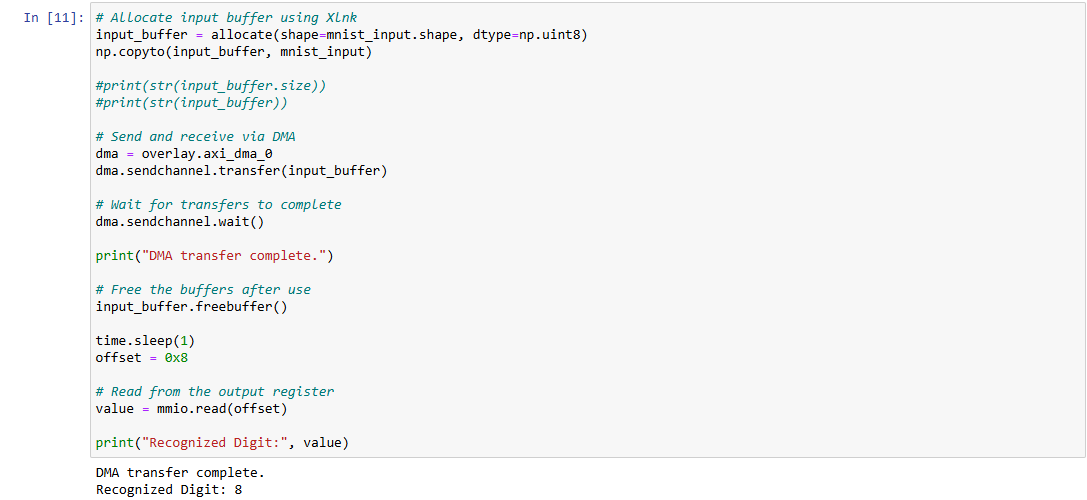
- CNN Execution: The hardware accelerator performs feature extraction and classification directly in the FPGA, offloading the computational load from the ARM processor.
- Result Display: The output is sent back to the ARM processor, where it can be viewed on a Jupyter Notebook interface hosted on the Linux-based PYNQ platform.
-
User Interaction
- Jupyter Interface: Users can interact with the system through a web browser, using Jupyter Notebooks for visualization and control.
- Python and PYNQ Framework: The use of PYNQ simplifies hardware-software integration, enabling seamless communication between the PS and PL.
-
Network Connectivity
- The system supports Ethernet for connecting the Arty Z7 to a host PC, allowing real-time monitoring and control.
Key Advantages of the System
- High Efficiency: The hardware accelerator processes MNIST digit recognition tasks with significantly reduced latency compared to software-only implementations.
- Portability: The compact design of the Arty Z7 makes this solution highly portable, and suitable for both educational and industrial applications.
- Ease of Use: The integration of Jupyter Notebooks provides a user-friendly interface for developers and non-technical users alike.
HW Setup

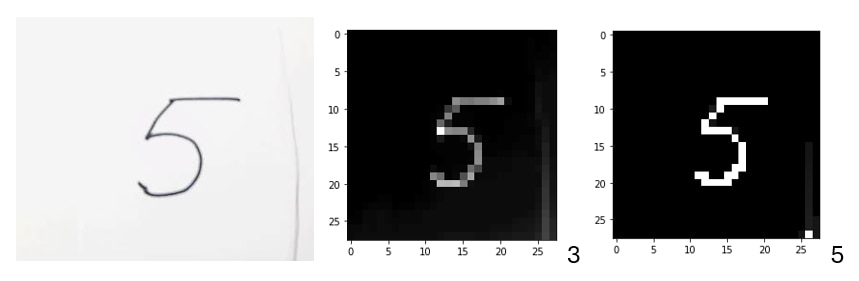
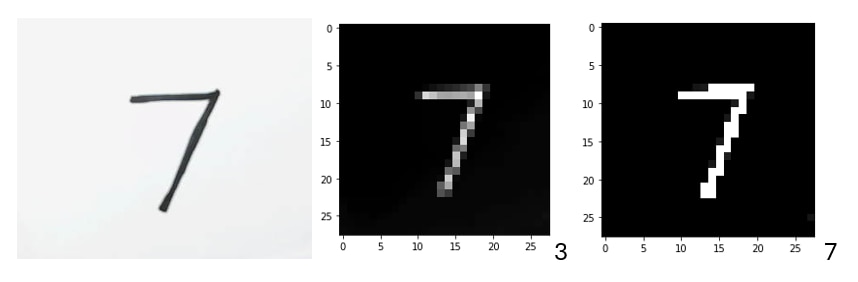
Flow to capture the image and feed it into the CNN HW Accelerator
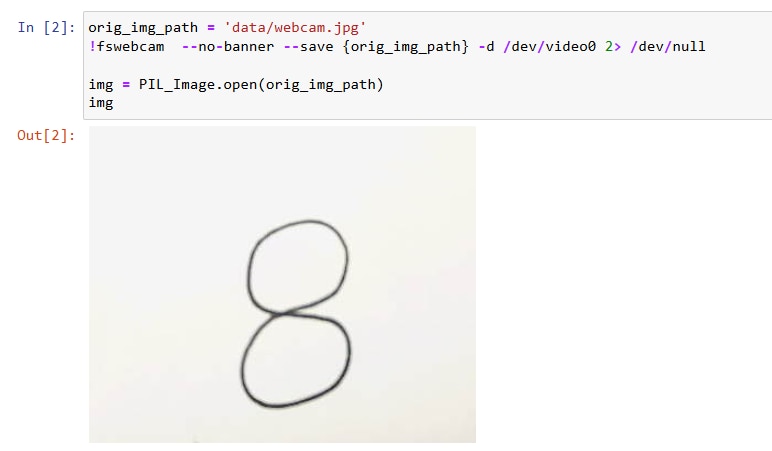
Converting the image into feedable form for the CNN HW Accelerator
Final Result
Pre-processing improves the accuracy of detection
Innovation for the Challenge
While many participants rely on pre-existing hardware accelerators and the Xilinx Deep Processing Unit (DPU), this project takes a different approach by building a custom CNN hardware accelerator from scratch. This deliberate design choice provides a transparent view into how the internals of machine learning (ML) accelerators function, giving developers and learners deeper insight into the underlying principles of AI hardware.
By creating the accelerator from the ground up, this project showcases:
- Core Building Blocks of ML Hardware: From convolution and activation functions to pooling and fully connected layers, each component of the CNN is meticulously implemented in the FPGA fabric. This approach not only enhances efficiency but also demystifies the operations that drive neural networks in hardware.
- Fine-Grained Optimization: Unlike generic accelerators, this custom implementation is tailored specifically for the MNIST dataset, leveraging optimizations such as reduced fixed-point data representation and efficient memory utilization to minimize hardware resource usage while maintaining accuracy.
- Educational Value: By exposing the internal workings of the CNN accelerator, this project serves as an excellent learning tool for understanding the trade-offs and design considerations involved in hardware-based AI systems.
This custom approach demonstrates a mastery of hardware design principles and highlights the effort to go beyond black-box solutions. It not only meets the challenge requirements but also inspires others by illustrating how ML accelerators work at a fundamental level. This sets the project apart as a standout contribution to the Element14 Eye on Intelligence Challenge, showcasing innovation, skill, and a commitment to advancing knowledge in the field of AI and embedded systems.
I thank the Element14 community for giving me this opportunity!

