


Using the Carry-Save Adder, A Generic Adder Tree
In this post I will show how to implement an efficient and generic adder tree, we need to compute the sum of N elements, where N can be any value. The numbers we add are also arbitrary precision fixed point values, all the same range but otherwise unconstrained.
We can represent the input data as an unconstrained array of unconstrained SFIXED, which requires VHDL-2008 support - with Vivado we can synthesize and implement this but we will not be able to simulate.
If we do not care about the final result's size or speed this can be written as simply as this (note the use of a variable inside a process, this is one of the few cases where using variables in VHDL designs makes sense):
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all; -- we need this package we introduced earlier for SFIXED type support
entity ADD is generic(LATENCY:INTEGER:=0); -- specify the desired adder tree latency here
port(CLK:in STD_LOGIC:='0';
I:in SFIXED_VECTOR; -- unconstrained vector of SFIXED, itself an unconstrained vector of STD_LOGIC - any number of inputs of arbitrary fixed point type
O:out SFIXED); -- unconstrained SFIXED output port
end ADD;
architecture TEST of ADD is
signal SO:SFIXED(I(I'low)'high+LOG2(I'length) downto I(I'low)'low); -- account for up to LOG2(I'length) bit growth
begin -- combinatorial N-input adder
process(I)
variable S:SFIXED(SO'range);
begin
S:=TO_SFIXED(0.0,SO); -- initialize S to 0.0
for K in I'range loop
S:=RESIZE(S+I(K),S); -- add every input to S
end loop;
SO<=S;
end process;
-- pipeline registers
sd:entity work.SDELAY generic map(SIZE=>LATENCY,
STYLE=>"reg")
port map(CLK=>CLK,
I=>RESIZE(SO,O),
O=>O);
end TEST;
But the implementation will use about twice as many LUT6es and carry chains compared with an optimal design and speed will be quite low and get lower as N gets larger - the design is too large and it does not scale well with N. With a latency of only one clock the maximum clock frequency and by consequence the throughput of the design will be low and inversely proportional to N.
We need to promote the use of 3-input Carry Save Adders if we want an efficient implementation and an easy way to do this (easy if you like recursion that is) is to group the inputs into subsets of 3, which will get added with instantiated CSA3 blocks. This decomposes an N-input adder, where N=3*K-2, N=3*K-1 or N=3*K into a first stage composed of K=(N+2) div 3 CSA3 modules, followed by a generic K-input adder second stage. We apply this recursively until the entire adder tree reduces to CSA3 modules, a ternary adder tree. This takes care of the size problem.
The speed problem can be addressed through pipelining - by adding registers at various stages in the ternary tree, we can increase the speed of the design at the expense of latency. For maximum possible speed we want to have every single CSA3 module with at least one register level. We have to be careful however and make sure that various branches of the ternary tree have exactly the same number of pipeline register levels. To keep the entire design as general and reusable as possible we will use a generic called LATENCY - the adder tree will have a latency of this many clocks and the register levels will be distributed inside the tree automatically. We will use the SDELAY and CSA3 generic building modules introduced in earlier posts, and of course the concept of recursive component instantiation, which is a natural fit for tree like structures:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all; -- we need this package we introduced earlier for SFIXED type support
entity ADD is generic(LATENCY:INTEGER:=0); -- specify the desired adder tree latency here
port(CLK:in STD_LOGIC:='0';
I:in SFIXED_VECTOR; –- unconstrained vector of SFIXED, itself an unconstrained vector of STD_LOGIC - any number of inputs of arbitrary fixed point type
O:out SFIXED); –- unconstrained SFIXED output port
end ADD;
architecture TEST of ADD is signal
SO:SFIXED(I(I'low)'high+LOG2(I'length) downto I(I'low)'low); –- account for up to LOG2(I'length) bit growth
begin
ta:case I'length generate
when 1|2|4|5=> –- for I'length=1, 2, 4 or 5 behavioral inference is good enough
-– combinatorial N-input adder
l1:process(I) variable S:SFIXED(SO'range);
begin
S:=TO_SFIXED(0.0,SO); –- initialize S to 0.0
for K in I'range loop
S:=RESIZE(S+I(K),S); –- add every input to S
end loop;
SO<=S;
end process;
-– pipeline registers
sd:entity work.SDELAY generic map(SIZE=>LATENCY,
STYLE=>"reg")
port map(CLK=>CLK,
I=>RESIZE(SO,O),
O=>O);
when 3=> –- for I'length=3 instantiate a Carry Save 3-input Adder
l3:entity work.CSA3 generic map(PIPELINE=>LATENCY>0)
port map(CLK=>CLK,
A=>I(I'low+0),
B=>I(I'low+1),
C=>I(I'low+2),
P=>SO);
-– extra pipeline registers if needed
sd:entity work.SDELAY generic map(SIZE=>MAX(LATENCY-1,0),
STYLE=>"reg")
port map(CLK=>CLK,
I=>RESIZE(SO,O),
O=>O);
when others=> –- for all other I'length values ADD recursively instantiates itself
ln:block
signal S3:SFIXED_VECTOR(0 to (I'length+2)/3-1)(I(I'low)'high+2 downto I(I'low)'low); –- account for 2 bit growth
begin
lk:for K in S3'range generate
al:entity work.ADD generic map(LATENCY=>MIN(LATENCY,1)) –- assign one pipeline level to first stage of CSA3s
port map(CLK=>CLK,
I=>I(I'low+3*K to I'low+MIN(3*K+2,I'length-1)), O=>S3(K));
end generate;
ah:entity work.ADD generic map(LATENCY=>MAX(LATENCY-1,0)) –- assign the remaining pipeline levels to second stage
port map(CLK=>CLK,
I=>S3,
O=>O);
end block;
end generate;
end TEST;
You have to keep in mind that unlike the numeric_std SIGNED type, which you would normally use for integers for example, SFIXED additions align the binary points of the operands and produce a result with a range that ensures a mathematically correct result. You will have to explicitly resize the result to address issues like overflows, rounding and so on. Note that the range of the output is also unconstrained and you will need to account for LOG2(N)=ceil(log2(N)) bits of bit growth to avoid overflows.
As an example here is how the synthesis result for a 9-input adder tree with LATENCY=2 looks like this:
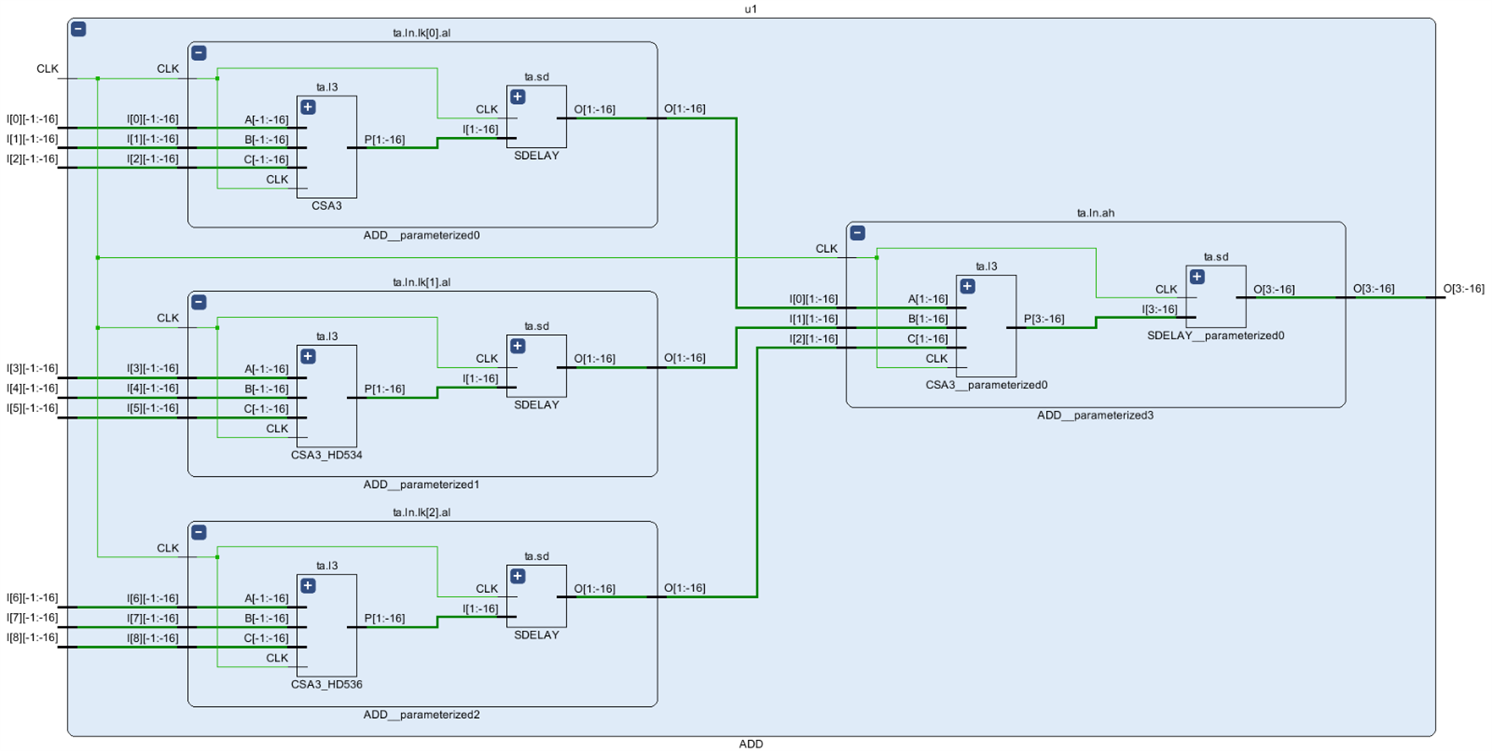
In conclusion, we have created a recursive module for an adder tree that uses mostly 3-input Carry Save Adders and for large trees requires about 50% of the number of LUT6es of a naive behavioral implementation. If pipelined properly with a minimum latency of LOG3(N) it can run at speeds of over 800MHz for any value of N.
The final post dedicated to Carry Save Adder applications will look at Constant Coefficient Multipliers, a very common case where one of the two factors being multiplied is a constant.
Back to the top: The Art of FPGA Design
Top Comments