


Using the Carry-Save Adder, The Constant Coefficient Multiplier
Multiplications in Xilinx FPGAs are done using DSP48s, which are primitives that consist of a 25x18 signed multiplier, a 25-bit preadder and a 48-bit postadder/accumulator. In UltraScale/UltraScale+ FPGA families the signed multiplier is 27x18 and the post adder has three inputs instead of just two. Depending on the FPGA size and family there are hundreds to thousands of such DSP48 primitives, that are able to do one multiply and two adds every clock at frequencies from 500 MHz to over 800 MHz.
I will need a few posts to talk about the DSP48s but before we do that I want to talk today about a particular type of multiplier where one of the two operands is always a constant - the Constant Coefficient Multiplier or KCM. While you can always use a DSP48 for that, tying one of the two factors to a constant value, there is a more efficient carry save adder fabric based implementation.
Let's assume that we want to do a signed 27x18 multiplication similar to the DSP48 one, but where the 18-bit factor is a constant. We will see that we can do this with the equivalent of only four adders, even less in some particular cases. A KCM multiplication can always be implemented with the classic shift and add algorithm but where we only add the shifted versions of the multiplicand for which the multiplier has non-zero bits. This means that we can use an adder tree of the kind we saw in the previous post and in theory we need to add up to N terms, where N is the bit size of the constant coefficient, 18 in our case. If we use simple ripple carry 2-input adders we will need up to 17 of them, when the coefficient is 0x3FFFF for example. But we have seen that using 3-input carry save adders that number can be reduced to only 9, an improvement of 2x in the size of the design. Another disadvantage of this solution is that the number of terms to be added depends heavily on the coefficient value - the more non-zero bits there are the more adders we will need.
However, with a clever math trick we can further reduce the number of adders, to a point where four 3-input adders are enough to implement a KCM for any 18-bit constant coefficient value. The trick is called Canonical Signed Digit (or bit in the binary case) representation. Rather than going into too much math detail, here is a link to a Wikipedia page that explains the basic idea:
https://en.wikipedia.org/wiki/Canonical_signed_digit
If you remember some earlier posts, subtraction is as easy to do as addition, including in the 3-input CSA version. Rather than using 0 and 1 to represent the constant multiplier we can use -1, 0 and +1. The number representation is no longer unique and among the large number of possible encodings there is always one where at least half of the bits are always 0. So we can always find a CSD representation for any constant coefficient where we need to add or subtract at most 9 terms of shifted multiplicands. We already know that a ternary adder tree of 9 terms has only four nodes - we just reduced the size of the design from the naïve 17 adders solution to one that requires only 4, a more than 4x improvement.
As an exercise let's build a 27x18 constant multiplier where the coefficient is sqrt(0.5)=0.70710678... A good fractional approximation is sqrt(0.5)≈46341/65536=0.7071075439453125, which is just 1E-6 bigger than the exact value.
The hexadecimal representation of 46341 is 0xB505, which has 7 non-zero bits so we do not even need the CSD representation with positive or negative bits, we can however chose how we create groups of three bits and we can take advantage of a common 3-input partial sum, which lets us implement the KCM for sqrt(0.5) with only 2 carry save adders. To do this we start with the binary representation of the constant coefficient:
sqrt(0.5)≈46341/65536=0xB505/0x10000
1111111
10.1234567890123456
00.1011010100000101
The 18-bit value can be written as the addition of three partial sums:
1111111
10.1234567890123456
00.1000010000000100
00.0010000100000001
00.0001000000000000
The first partial term is a 3-input sum of the multiplicand right shifted by 1, 6 respectively 14 bits. The second term is just the first term right shifted by 2 bits, while the third partial term is simply the multiplicand right shifted by 4 bits.
If I is the variable input and O is the output, we can compute the KCM O<=sqrt(0.5)*I with only two 3-input adders using an intermediate result X:
X<=SHIFT_RIGHT(I,1)+SHIFT_RIGHT(I,6)+SHIFT_RIGHT(I,14)
O<=X+SHIFT_RIGHT(X,2)+SHIFT_RIGHT(I,4)
We can reuse now the CSA3 module created earlier and write the KCM in VHDL very easily:
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all;
entity KCM is -- O=Sqrt(0.5)*I
generic(PIPELINE:BOOLEAN:=TRUE); -- LATENCY will be 2 if PIPELINE else 0
port(CLK:in STD_LOGIC:='0';
I:in SFIXED;
O:out SFIXED);
end KCM;
architecture FAST of KCM is
signal X:SFIXED(I'high downto I'low-14);
signal Y:SFIXED(I'range);
begin
-- X=SHIFT_RIGHT(I,1)+SHIFT_RIGHT(I,6)+SHIFT_RIGHT(I,14)
a1:entity work.CSA3 generic map(PIPELINE=>PIPELINE)
port map(CLK=>CLK,
A=>SHIFT_RIGHT(I,1),
B=>SHIFT_RIGHT(I,6),
C=>SHIFT_RIGHT(I,14),
P=>X);
-- Y is I delayed by one clock if PIPELINE=TRUE
sd:entity work.SDELAY generic map(SIZE=>BOOLEAN'pos(PIPELINE))
port map(CLK=>CLK,
I=>I,
O=>Y);
-- O=X+SHIFT_RIGHT(X,2)+SHIFT_RIGHT(Y,4)
a2:entity work.CSA3 generic map(PIPELINE=>PIPELINE)
port map(CLK=>CLK,
A=>X,
B=>SHIFT_RIGHT(X,2),
C=>SHIFT_RIGHT(Y,4),
P=>O);
end FAST;
Note again the use of the arbitrary fixed point precision unconstrained SFIXED type, this module will multiply a signed fixed point input I of any range by 46341/65536 and then truncate the result to the arbitrary range specified by O. With the PIPELINE generic we can have either a purely combinatorial implementation or one with a latency of 2 clocks which will run easily at speeds in the 800MHz range. Here is the synthesis result when the I and O ports have both a SFIXED(1 downto -16) range and PIPELINED is TRUE:
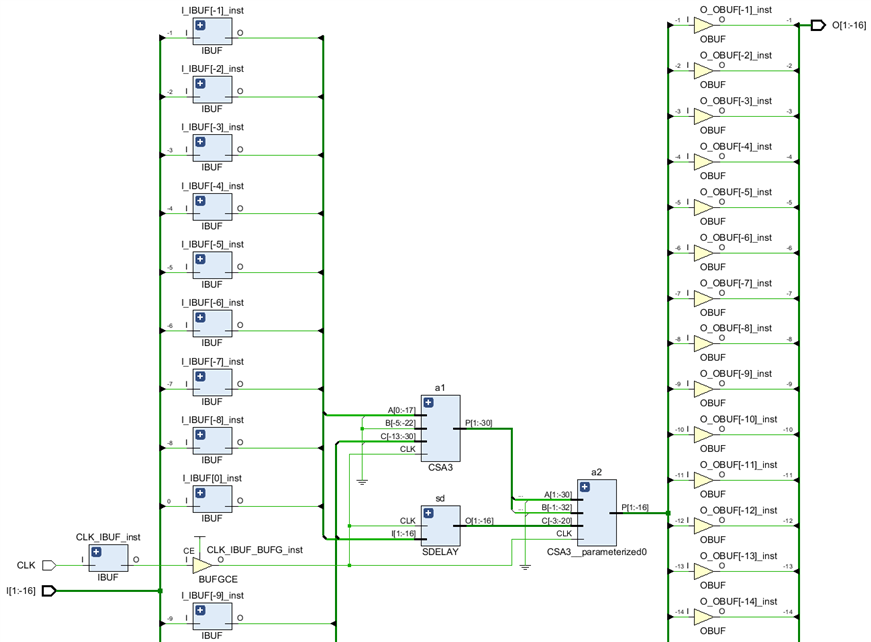
This concludes the series of posts dedicated to the efficient 3-input carry save adder and also the quick look at various CLB primitives like LUT6, SRL16 and CARRY8. We will continue next week by starting to discuss the DSP48 multiply/accumulate primitive.
Back to the top: The Art of FPGA Design
