


The basic building blocks on the FPGA implementation side
The three main FPGA building blocks that are being used to implement the adders, multipliers and delays of DSP algorithms in hardware are completely different, the 6-input look up table, the flip flop and the DSP48. While there is some kind of equivalence, the apparent similarities can be deceptive. We have already seen that we cannot operate with real or complex numbers in the mathematical sense of infinite precision, we can only do computations with finite precision numbers. So an m-bit delay will be implemented with m FFs for example, while a multiplication will be done with a DSP48 as long as the operands are less or equal to a particular maximum size. But the biggest difference is that while mathematical computations are instantaneous and occur outside time, real world ones do not. It takes a finite, non-zero amount of time for anything to happen, even something as simple as moving a value from one point in space to another. As a matter fact, this moving of data, which is called routing in FPGA parlance, takes more time than the actual additions and multiplications do and is the main speed limiting factor.
Let's consider the adder. First of all, the generic N-input adder, while nice from a mathematical point of view, is not something we would want to build in hardware because it is not scalable, its speed is inversely proportional to N if we implement it as a chain of 2-input adders or with log2(N) if implemented as a binary tree. We want the throughput, or speed, to be independent of N. So we will restrict ourselves to using only 2-input adders:

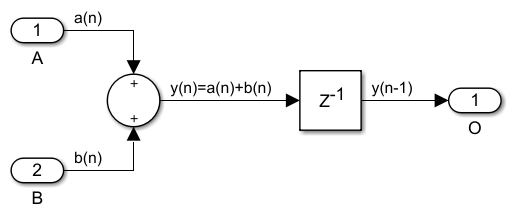
To the left is the mathematical adder, where you get the result y(n) as soon as the a(n) and b(n) inputs are available. To the right is the physical pipelined adder. It takes time, let's say 1.0 ns for y(n) to be computed when a(n) and b(n) become available and then you need to store this result somewhere before the next a(n+1) and b(n+1) input samples arrive on the next clock. The delay, which acts as a pipeline register here, serves this purpose. The point is that y(n) is not available right now to do other computations in parallel with the addition, only the previous y(n-1) result is. To achieve the highest possible speed and make that scalable or independent of the design size N, every adder will have to be followed immediately by a pipeline register. The original mathematical implementation of the FIR does not have these registers between the chained adders and this will have to be addressed.
A similar situation exists for the second block, the multiplier:

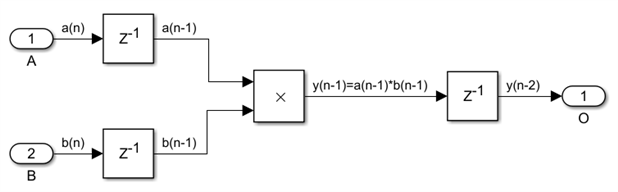
Except that in this case we need two pipeline register levels to achieve the maximum possible speed. At any given moment in time, only the current a(n) and b(n) inputs and the product y(n-2) of two clock periods ago are available. The current product y(n) and the previous one y(n-1) are still in the process of being calculated and cannot be used for anything else.
The delay is the only block that we can use as such in both cases. But even here there are implementation considerations that will matter. In particular, a multi-clock delay, a chain of two or more delays where the intermediate partial delays or taps are not used for anything else can be implemented very efficiently in FPGAs. The smallest FPGA fabric building blocks or primitives are the 6-input look up table, also called LUT6es and the 1-bit FF. There is a ratio of 1 to 2 between these fabric resources, for every LUT6 there are two FFs we can use. The 6-input LUT can implement a 1-bit delay chain of 1 up to 32 levels or two such chains of 1 up to 16 levels as long as both are of the same length if used this way, the LUT6 primitives are called SRL16 respectively SRL32. This is significant because we can replace up to 32 FFs with a single LUT6 primitive. But there is a small catch here, like in the adder case, this LUT6 based delay chain also needs to be pipelined if you want to achieve the best performance and maintain scalability. This means that the last delay in the chain will become a FF while the rest can be implemented in a LUT6. The resource utilization is still proportional to N but with a granularity of 16 and long delay chains can generally be implemented very efficiently.
If our data samples are represented with m bits, the following table shows how many resources are needed for a delay chain of size N:
| N | 1 | 2..17 | 18..33 | 34..49 | 50..65 |
|---|---|---|---|---|---|
| LUT6es | 0 | m/2 | m | 3m/2 | 2m |
| FFs | m | m | m | m | m |
As a general rule of thumb, for a delay line N levels deep and m bits wide the LUT6 utilization is m*ceil((N-1)/16) and the FF number is m. It actually gets even better than this. We will soon encounter delay lines of a given length N but where we need to access any internal tap, not just the last one. As long as we access a single tap at a time, not necessarily the same one every clock, something described by the following diagram, we can achieve that for free without any extra resources being used:
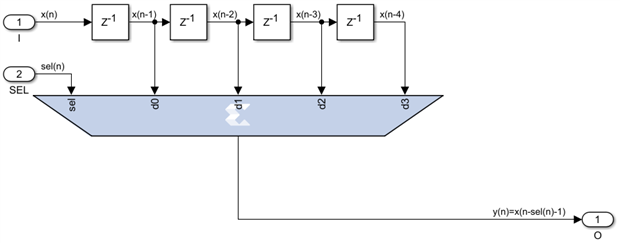
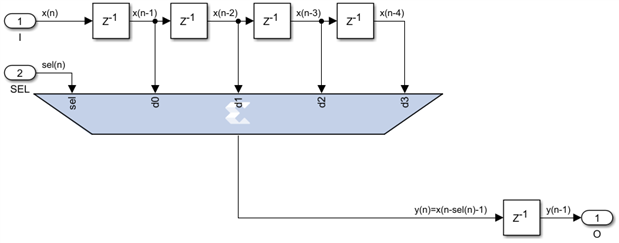
On the left we have the mathematical equivalent of the tapped delay line and on the right the efficient hardware implementation. As long as we still use the final pipelining register level like on the right side of the diagram above, maximum speed can always be achieved no matter how large N is and the utilization numbers are exactly the same as for the fixed size delay line - the multiplexer is essentially free.
Finally, the adders, the multipliers and the delays are not completely independent of each other. The other major FPGA primitive is called generically the DSP48 and apart from a signed multiplier, it also contains a post-adder, a pre-adder and a lot of pipeline registers. There are also three distinct flavors called DSP48E1, DSP48E2 and DSP58 which are used respectively in the last three generations of Xilinx FPGAs, called 7-series, UltraScale/UltraScale+ and Versal. The way these sub-elements are used and connected is highly configurable, including dynamically at run-time. This is an oversimplified view of what is available inside every DSP48 primitive:

The pre-adder is 25-bit wide for DSP48E1 and 27-bit wide for DSP48E2 and DSP58. The multiplier is signed 25x18, 27x18 and 27x24 respectively, and the post adder is 48-bit wide for DSP48E1 and DSP48E2 and 58-bit for DSP58. Every single register can be bypassed and has an independent clock enable and synchronous reset, which gives us a lot of flexibility and implementation options. The pre-adder and post-adder are also very flexible and their operation can be modified dynamically. The point is that once we decide to use the DSP48 multiplier, we get all these other hardware resources for free so we want to create designs where as many adders and delays are also absorbed into the DSP48 primitive. However, this is only possible if we target the DSP48 architecture with our algorithm implementation.
.
As a matter of fact, the simple single rate FIR algorithm example we have started with can be implemented entirely with DSP48 primitives and no fabric resources at all, even the fully pipelined generic and scalable implementation that we will design in the next couple of posts.
Back to the top: The Art of FPGA Design Season 2
-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children