


The Single Rate even-symmetric FIR
We have looked so far at the simplest and most generic FIR possible, the single rate non-symmetric FIR filter. But many FIR filter implementations have more particular structures and taking advantage of these can improve the filter efficiency in terms of resource utilization. The simplest possible variation is coefficient symmetry. As a matter of fact, more than half of the FIRs you will ever encounter will be symmetric in one form or another, and the general rule for symmetric FIRs is that you can always reduce the number of multiplications needed by a factor of 2x.
There are actually four variations of coefficient symmetry, symmetric and anti-symmetric, and both can have an even or odd number of coefficients. For now, we will consider only the case of symmetric, even-order FIRs, where the number of coefficients and the filter order is N=2*K. An example of such filter for K=4 and N=8 is shown below:

We will start making some changes to this filter, without affecting its functionality. We will fold the second half of the input delay line on top of the first half and take advantage of the associativity and commutativity properties of the addition to rearrange the post-adder. I have added one extra input delay at the very end, marked in grey, which makes no difference because x(n-10) is not used anywhere:
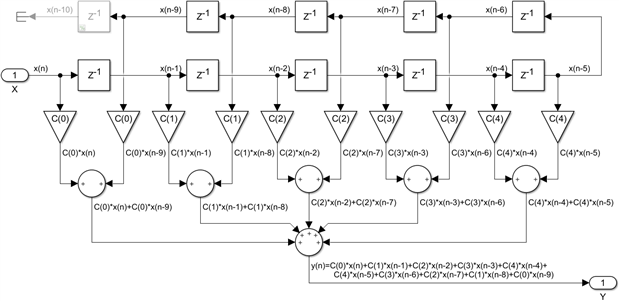
The next step is to swap the order of multiplications and additions in each transversal branch, a mathematician would call this the distributivity of multiplication over addition. The net effect of this operation is a reduction in the number of multiplications by a factor of 2x and this is typical for all symmetric FIRs:
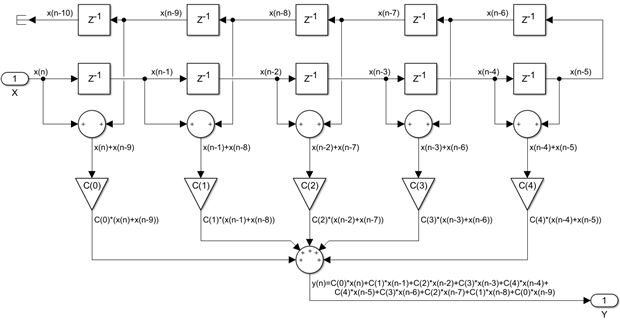
Now it is the moment where we can address the other three symmetric FIR variations. If the filter is anti-symmetric, the five pre-adders would be replaced by five pre-subtractors, but the general structure would remain exactly the same. In both cases, if the FIR is odd, that is N=2*K-1, all we have to do is remove the last delay in the forward half of the input delay line and the last pre-adder and we get the odd symmetric filter. If the FIR is both odd and also anti-symmetric, then C(4) will be zero. In all cases, a filter of any size can be built by cascading the following basic building block if we replace the 5-input post-adder with a chain of five 2-input adders:

We have now a generic implementation for any symmetric FIR of any size but it is not scalable, we need to pipeline it. The next diagram shows the transversal and longitudinal pipeline cuts where we will add more registers, but now there are wires crossing the transversal cuts in both directions and we will have to remove delays from the portion of the input delay line that is going backwards:
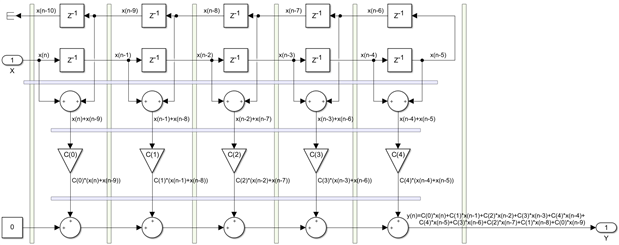
The delays that were removed are now marked as z−0 , which are essentially wires. The design is now fully pipelined, including one extra register level for the pre-adders:
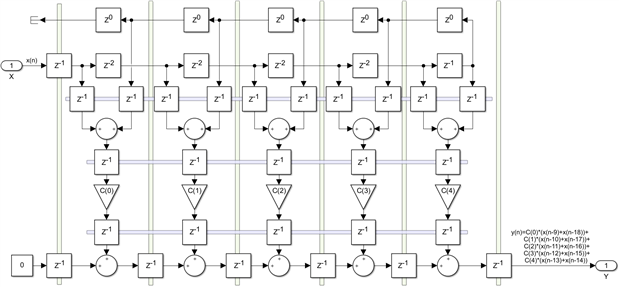
The net effect of all these steps is that we have saved half of the multiplications, while the number of adders has remained the same. But it gets even better. The DSP48 primitive has the pre-adders built in, including their pipelining registers. The diagram below shows the previous one, with the delays, adders and multipliers colored with a different color for each DSP48. I have also labeled the delays with the names of the dedicated DSP48 registers, and I have removed one redundant input delay and pushed some registers around. There is one more change we need to make now. Since we implemented the input delay line with the DSP48 dedicated A cascade and there is no way to connect the ACOUT output of the last DSP48 to the D input of any DSP48, we need to use a parallel fabric based delay, shown in white, to drive all the D inputs. The value of this delay is 2*K-1, two delays for each one of the K DSP48 steps minus the delay I have removed:
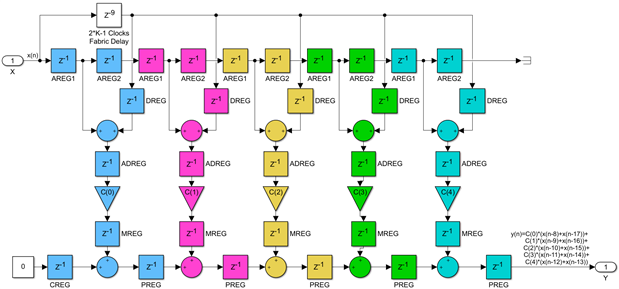
In conclusion, we can add another fundamental DSP48 based FIR building block to our list, this one for symmetric FIRs. As it was the case with the systolic non-symmetric FIR, virtually all the resources needed are already present in the DSP48s and we can build symmetric FIRs of any size with a chain of such blocks:
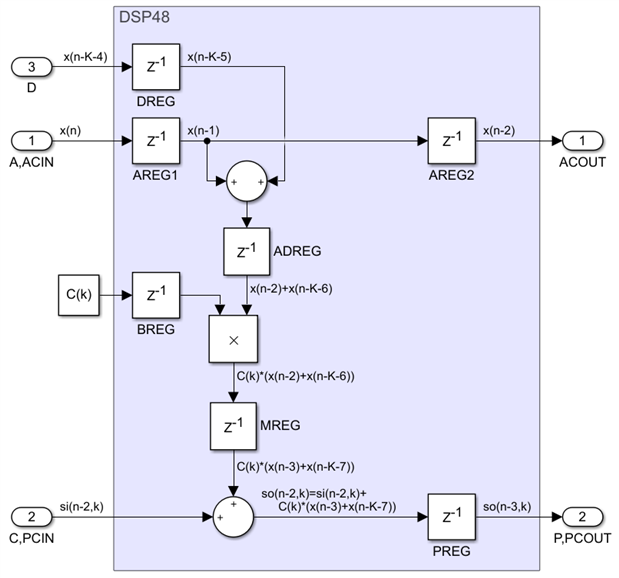
It might appear that this design is not scalable because the same signal drives the D inputs of all DSP48s in the chain, very much so like the non-symmetric transpose FIR variant we discussed earlier. For K values greater than 20 this will start impacting the clock speed. But there is a significant difference, a fabric delay of 2*K-1 clocks drives all D inputs, and there are more than enough registers there to create a pipelined signal distribution tree of any size. The designer could do this explicitly, but he could also let the Vivado tools do this automatically in the physical optimization implementation step, which has an option for doing retiming to improve the speed of the design. Either way, a symmetric FIR of any size N=2*K can always be implemented with K DSP48s and run at the maximum possible clock speed - this design is also scalable. The latency of this FIR implementation will be K+3 clocks, one more compared with the non-symmetric systolic because of the need to pipeline the pre-adders.
Back to the top: The Art of FPGA Design Season 2
