


Instantiating LUT6 Primitives Part 2
Today I will show a couple of examples where LUT6 primitive instantiations make sense. To keep things short and simple these are somewhat artificial examples but situations like these tend to show up all the time in hardware designs. Let's say we need a 48-input AND function. This can be coded very easily behaviorally, especially if we take advantage of the new VHDL-2008 features:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity WideAND is
port(CLK:in STD_LOGIC;
I:in STD_LOGIC_VECTOR(47 downto 0);
O:out STD_LOGIC);
end WideAND;
architecture TEST of WideAND is
signal RI:STD_LOGIC_VECTOR(I'range):=(others=>'0');
begin
process(CLK)
begin
if rising_edge(CLK) then
RI<=I;
O<=and RI; -- VHDL-2008 feature
end if;
end process;
end TEST;
I have registered both the inputs and the outputs so that we can estimate the speed as well as the size of the implementation but we are only interested in the combinatorial portion of the design, which looks like this:
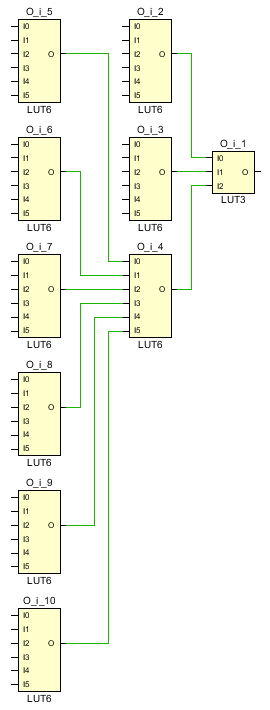
The design uses 10 LUTs and the critical timing path is 3 logic levels. It looks like there is no better solution using less resources than that. However, each Xilinx Slice contains an 8-bit dedicated carry chain logic, which is normally used to implement counters, adders, accumulators and so on. The primitive is called CARRY8 and the functionality can be seen in figure 2-4 of the UltraScale Architecture CLB User Guide UG574:
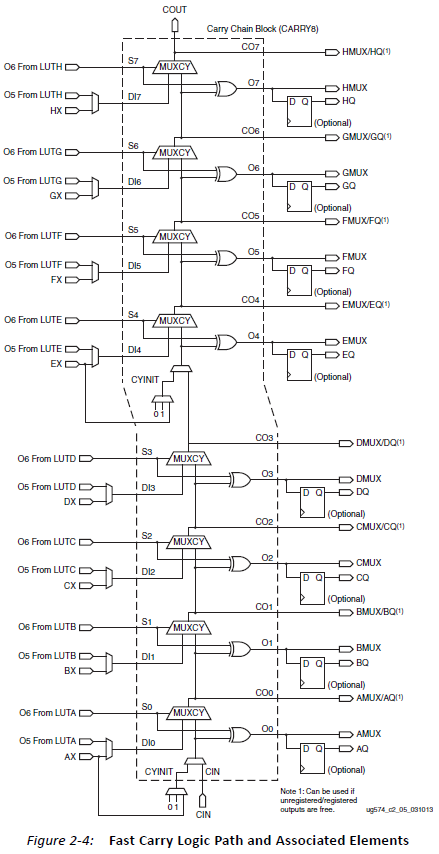
It is possible to use this essentially free resource for other logic functions, for example as an 8-input AND or OR gate, implemented with the MUXCY portion of the CARRY8. The design version below uses only 8 LUT6es and one CARRY8 to implement the 48-input AND:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
library UNISIM;
use UNISIM.VComponents.all;
entity WideAND is
port(CLK:in STD_LOGIC;
I:in STD_LOGIC_VECTOR(47 downto 0);
O:out STD_LOGIC);
end WideAND;
architecture TEST of WideAND is
constant I0:BIT_VECTOR(63 downto 0):=X"AAAAAAAAAAAAAAAA";
constant I1:BIT_VECTOR(63 downto 0):=X"CCCCCCCCCCCCCCCC";
constant I2:BIT_VECTOR(63 downto 0):=X"F0F0F0F0F0F0F0F0";
constant I3:BIT_VECTOR(63 downto 0):=X"FF00FF00FF00FF00";
constant I4:BIT_VECTOR(63 downto 0):=X"FFFF0000FFFF0000";
constant I5:BIT_VECTOR(63 downto 0):=X"FFFFFFFF00000000";
signal RI:STD_LOGIC_VECTOR(I'range):=(others=>'0');
signal S,CO:STD_LOGIC_VECTOR(7 downto 0);
begin
process(CLK)
begin
if rising_edge(CLK) then
RI<=I;
O<=CO(7);
end if;
end process;
lk:for K in S'range generate
l6:LUT6 generic map(INIT=>I0 and I1 and I2 and I3 and I4 and I5)
port map(I0=>RI(6*K+0),I1=>RI(6*K+1),I2=>RI(6*K+2),I3=>RI(6*K+3),I4=>RI(6*K+4),I5=>RI(6*K+5),O=>S(K));
end generate;
cy:CARRY8 port map(CI=>'1', – 1-bit input: Lower Carry-In
CI_TOP=>'1', – 1-bit input: Upper Carry-In
DI=>8x"00", – 8-bit input: Carry-MUX data in
S=>S, – 8-bit input: Carry-mux select
CO=>CO, – 8-bit output: Carry-out
O=>open); – 8-bit output: Carry chain XOR data out
end TEST;
The synthesis result is 20% smaller and as fast as the behavioral implementation so we have a better design solution:
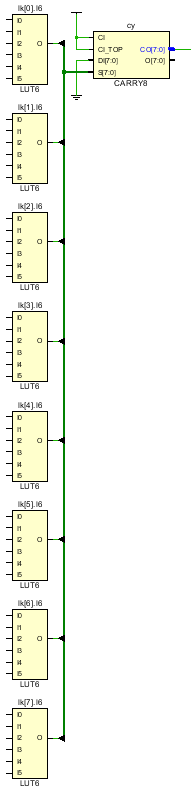
Since the CARRY8s can be cascaded this idea can be extended to implement AND or OR gates with virtually any number of inputs.
The second example is a particular case of eight 7-input XOR gates that share a common input. The behavioral code uses 16 LUT6es since you need two of them to implement a XOR7:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity XOR7 is
port(CLK:in STD_LOGIC;
I0,I1,I2,I3,I4,I5:in STD_LOGIC_VECTOR(7 downto 0);
I6:in STD_LOGIC;
O:out STD_LOGIC_VECTOR(7 downto 0));
end XOR7;
architecture TEST of XOR7 is
signal RI0,RI1,RI2,RI3,RI4,RI5:STD_LOGIC_VECTOR(I0'range):=(others=>'0');
signal RI6:STD_LOGIC:='0';
begin
process(CLK) – register all inputs so that we can measure fMAX
begin
if rising_edge(CLK) then
RI0<=I0;RI1<=I1;RI2<=I2;RI3<=I3;RI4<=I4;RI5<=I5;RI6<=I6;
end if;
end process;
process(CLK)
begin
if rising_edge(CLK) then
for K in O'range loop
O(K)<=RI0(K) xor RI1(K) xor RI2(K) xor RI3(K) xor RI4(K) xor RI5(K) xor RI6; – eight 7-inpout XOR gates with a shared input
end loop;
end if;
end process;
end TEST;
Here again we can take advantage of the free CARRY8 resource, this time using the XORCY part:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
entity XOR7 is
port(CLK:in STD_LOGIC;
I0,I1,I2,I3,I4,I5:in STD_LOGIC_VECTOR(7 downto 0);
I6:in STD_LOGIC;
O:out STD_LOGIC_VECTOR(7 downto 0));
end XOR7;
architecture TEST of XOR7 is
signal RI0,RI1,RI2,RI3,RI4,RI5:STD_LOGIC_VECTOR(I0'range):=(others=>'0');
signal RI6:STD_LOGIC:='0';
signal S,DI,XO:STD_LOGIC_VECTOR(7 downto 0);
begin
process(CLK) – register all inputs so that we can measure fMAX
begin
if rising_edge(CLK) then
RI0<=I0;RI1<=I1;RI2<=I2;RI3<=I3;RI4<=I4;RI5<=I5;RI6<=I6;
O<=XO;
end if;
end process;
lk:for K in S'range generate
constant I0:BIT_VECTOR(63 downto 0):=X"AAAAAAAAAAAAAAAA";
constant I1:BIT_VECTOR(63 downto 0):=X"CCCCCCCCCCCCCCCC";
constant I2:BIT_VECTOR(63 downto 0):=X"F0F0F0F0F0F0F0F0";
constant I3:BIT_VECTOR(63 downto 0):=X"FF00FF00FF00FF00";
constant I4:BIT_VECTOR(63 downto 0):=X"FFFF0000FFFF0000";
constant I5:BIT_VECTOR(63 downto 0):=X"FFFFFFFF00000000";
begin
l6:LUT6 generic map(INIT=>I0 xor I1 xor I2 xor I3 xor I4 xor I5)
port map(I0=>RI0(K),I1=>RI1(K),I2=>RI2(K),I3=>RI3(K),I4=>RI4(K),I5=>RI5(K),O=>S(K));
end generate;
DI<=(others=>RI6);
cy:CARRY8 port map(CI=>RI6, – 1-bit input: Lower Carry-In
CI_TOP=>RI6, – 1-bit input: Upper Carry-In
DI=>DI, – 8-bit input: Carry-MUX data in
S=>S, – 8-bit input: Carry-mux select
CO=>open, – 8-bit output: Carry-out
O=>XO); – 8-bit output: Carry chain XOR data out
end TEST;
This time we went from using 16 LUT6es to using only 8, again with no speed penalty, a very significant reduction especially if this module is repeated numerous times in a design.
The lesson here is that targeting the FPGA architecture can sometimes improve a design's performance significantly but there is a price to be payed in code complexity due to lower level coding style and even primitive instantiations. There must be a significant payoff in the speed/area performance level of the design to justify that and it is always a good idea to restrict this low level HDL code portion to the bottom of the design hierarchy and make these sub-modules as generic and reusable as possible.
Back to the top: The Art of FPGA Design
-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

DAB
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children