


The DSP48 Primitive - Inferring larger multipliers
The DSP48E2 primitive contains a signed 27x18 multiplier, any signed multiplier up to this size can be implemented with just one such primitive. If we need larger multipliers we can achieve that with multiple DSP48s.
The way larger multipliers are built uses a feature of the DSP48 primitive in which the 48-bit dedicated P cascade output of one DSP48 is right shifted by 17 bits before being added to the partial product calculated in the next DSP48. Using this technique a 27x35 multiplier can be decomposed into a 27x(18+17) one, where the a 27x17 partial product is computed with one DSP48 and the result is right shifted by 17 bits before being added to the second 27x18 partial product.
Fortunately, Vivado Synthesis is able to infer such a multi-DSP48 multiplier, including the proper pipelining from behavioral HDL code so there is no need to use primitive instantiations. The following code example shows a generic behavioral multiplier, where the two operands and the product can be arbitrary precision fixed point numbers of any size. For multipliers up to 27x18 a single DSP48 will be inferred, while for up to 35x27 ones two DSP48s are used. The pipelining of the design is controlled with the LATENCY generic, for full speed (meaning for example 891MHz in an UltraScale+ FPGA, fastest sped grade -3) performance LATENCY should be set to 3 for single DSP48 multipliers and 4 for higher precision, two DSP48 ones:
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all;
entity GENMULT is
generic(LATENCY:INTEGER:=4); -- should be 3 for one DSP48 (up to 27x18) and 4 for two DSP48s (up to 35x27)
port(CLK:in STD_LOGIC:='0';
A:in SFIXED(34 downto 0);
B:in SFIXED(26 downto 0);
P:out SFIXED(61 downto 0)); -- P can be any size, the result will be resized
end GENMULT;
architecture FAST of GENMULT is
signal RA:SFIXED(A'range):=TO_SFIXED(0.0,A);
signal RB:SFIXED(B'range):=TO_SFIXED(0.0,B);
signal PL:SFIXED_VECTOR(2 to LATENCY)(P'range):=(others=>TO_SFIXED(0.0,P));
begin
process(CLK)
begin
if rising_edge(CLK)then
--first pipeline level
RA<=A;
RB<=B;
--second pipeline level
PL(2)<=RESIZE(RA*RB,P);
--the rest of pipeline levels
for K in 3 to LATENCY loop
PL(K)<=PL(K-1);
end loop;
end if;
end process;
P<=PL(LATENCY);
end FAST;
The port sizes are set for the largest multipliers that can be built with two DSP48s but they could also be left unconstrained if you want and then any arbitrary fixed point multiplier up to 35x27 with any LATENCY greater or equal to 2 could implemented with this single design. It is worthwhile pointing out the way the proper pipelining is achieved here. Rather than explicitly describing the DSP48 internal pipeline registers, which gets really tricky when you have two cascaded ones like it is the case here, we can describe the behavioral single multiplication operation as a combinatorial function between two register levels, add one or more pipeline registers at the output and if the synthesis retiming option is turned on the synthesis tool will take care of both decomposing the single multiplication into two DSP48s and pushing the output registers into them to achieve optimal pipelining.
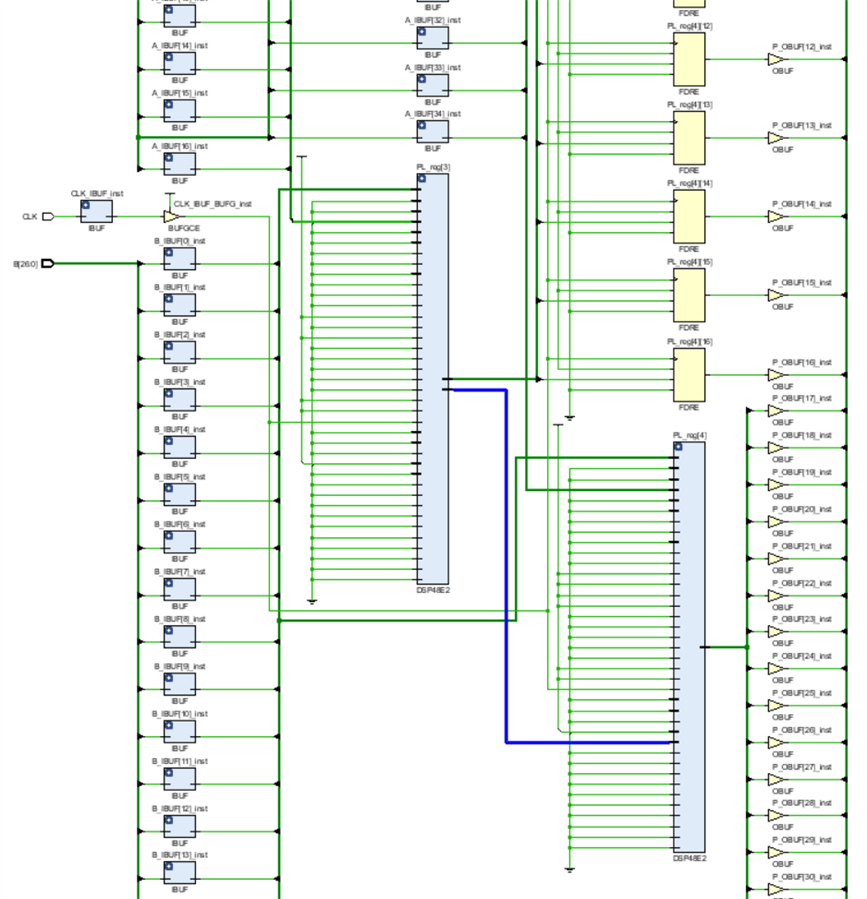
The implementation result is very good, two DSP48 and 17 FFs, which are needed because the lower 17 LSBs of the result arrive one clock earlier from the first DSP48 and need to be delayed by one clock in the fabric, but otherwise no other fabric resources are needed. The highlighted bus between the two DSP48s connects the PCOUT output port of the first to the PCIN input port of the second and this is where the partial sum is also right shifted by 17 bits:
In the next post we will look at efficient implementations of complex multipliers.
Back to the top: The Art of FPGA Design
Top Comments