


Multichannel and Overclocking FIRs - The Single Rate Symmetric Case
In the last post I created an overclocked or semi-parallel implementation of a systolic, non-symmetric FIR, where each DSP48 in the chain implements M taps of the filter. The filter sample rate is M times slower than the system clock rate, but the device utilization is also M times smaller, N/M DSP48s instead of the normal N, where N is the filter order.
Many times the FIR filter is symmetric and the DSP48 pre-adder feature lets us take advantage of this symmetry and reduce the number of multiplications by a factor of 2, see Posts 6 and 7 for the even-symmetric, respectively odd-symmetric case. We would of course like to do the same thing for the overclocked FIR.
We not only have the two cases where the filter order N is even or odd, but there are also three slightly different implementations for the cases when the overclocking factor M is 2, 3 or larger, so we have a total of six unique designs. Rather than deriving the non-pipelined and then the pipelined version for each one, I will simply present the six final efficient implementations, with the resources mapped to DSP48s and SRL16 shift registers. The designs are also larger than what we had encountered so far, so if you see a fuzzy block diagram, just click on the image and a better one will pop up.
For all six designs, I will use a chain of K=3 DSP48s as an example. The first and last DSP48s have slightly different configurations than the middle one. For larger filters with N=2*K respectively N=2*K-1, where K is the number of DSP48s in the chain, simply replicate the middle block as needed. Like in all previous designs, I colored the resources that should go into the same DSP48 with the same background color.
Let's start with the even-symmetric case, when N=2*K and the overclocking factor M is larger than 3. I will use M=4 as an example but this design can be used as is for any M that is 4 or larger, all you have to do is increase the length of the addressable shift registers and adjust the M-1 clock delays in the data valid path:
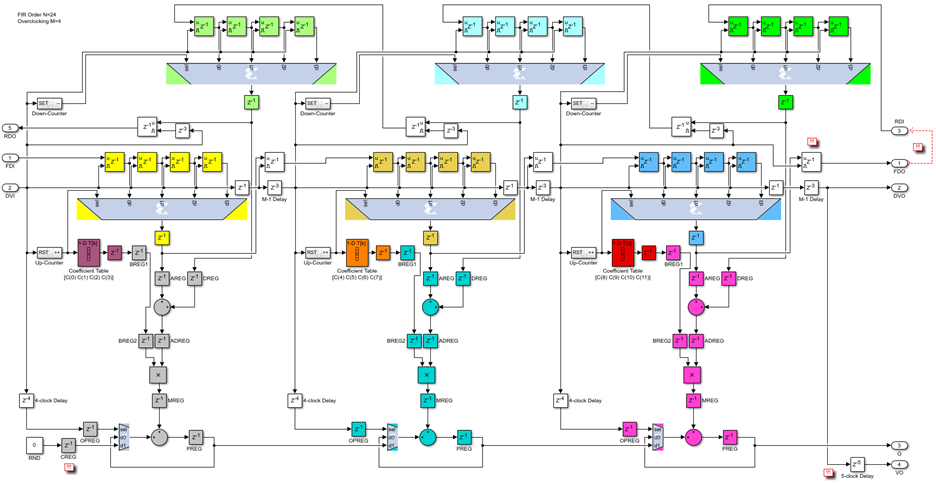
The key differences compared to the non-symmetric version are the use of the DSP48 pre-adders, including the D input port and the DREG and ADREG pipeline registers. We arrive at this structure by using four rather than just three longitudinal pipeline cuts. There is also a second chain of SRL16 addressable shift registers, with data moving in the opposite direction from one DSP48 to the next. These reverse data shift registers are addressed by a down-counter, which runs in sync with the up-counter addressing the forward data shift registers and the coefficient ROM tables, except that this counter counts from M-1 down to 0, rather than from 0 to M-1. The other points of interest in the design are marked with a red triple exclamation mark block. They point for example to why the first DSP48 is different from all the others - it uses the registered C input port rather than the dedicated PCOUT to PCIN cascade. The other differences are in the last DSP48 in the chain. First, the register capturing the output of the forward shift register for the next DSP48 in the chain has a slightly different clock enable, which arrives one clock earlier. The output of this register is then fed back into the reverse shift register chain. Finally, a 5-clock delay register compensates for the effect of the pipeline cuts and generates a data valid output signal which is in phase with the filter output samples.
The odd-symmetric case is a slight modification of the even-symmetric design:

The modifications required to turn the even filter into an odd one are all in the last DSP48 in the chain. There is no data capture register anymore, the output of the forward shift register drives the input of the reverse shift register directly. This has the effect of the same data sample being multiplied with the last coefficient C(11) twice, so this is compensated by dividing this coefficient by a factor of 2 in the coefficient ROM table.
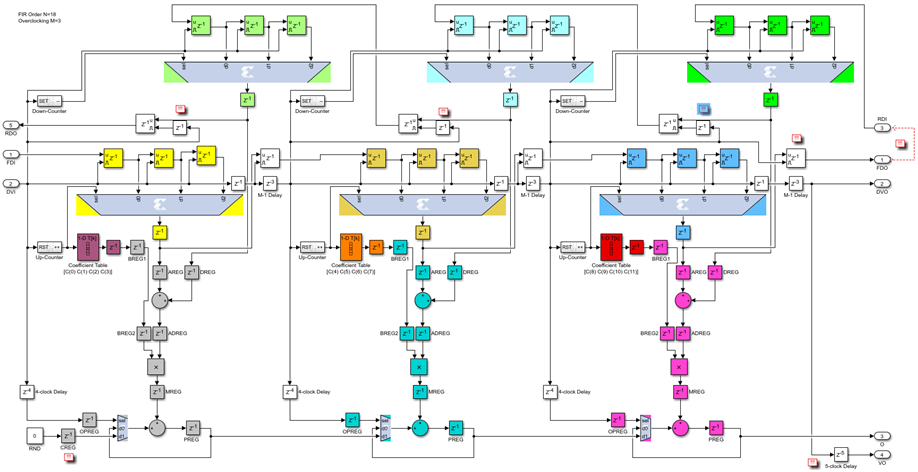
The case of the even-symmetric FIR when the overclocking factor M=3 differs from the previous one in one small respect, the clock enables for the output data capture registers for the reverse delay line, which were delayed by 3 clocks, are now delayed by only one clock:
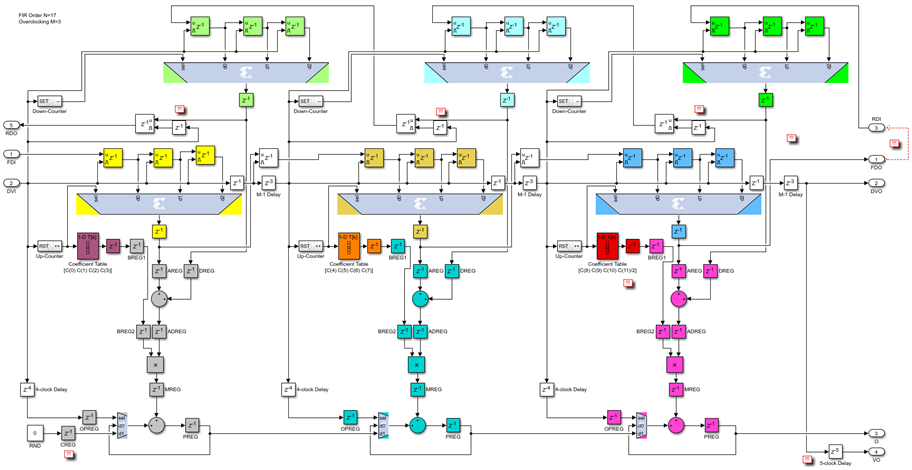
Similarly, the odd-symmetric M=3 case differs from the earlier M=4 odd version by the same minor change:
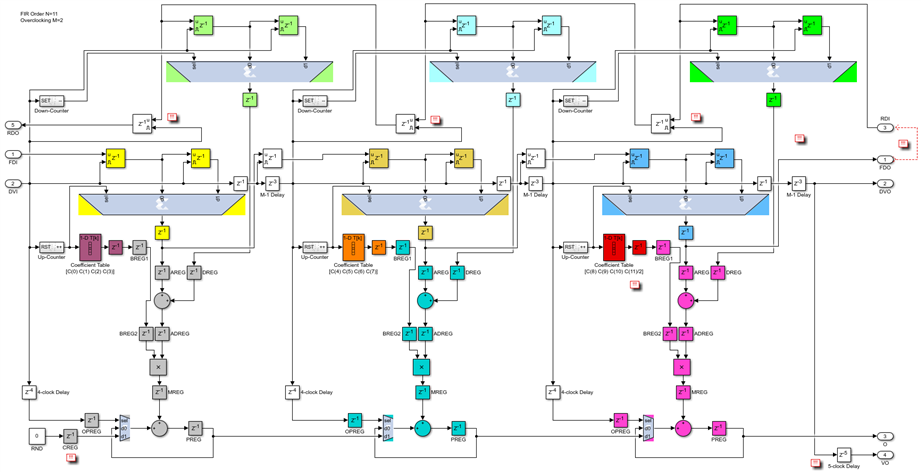
Finally, the even symmetric M=2 case has the same clock enables delayed now by 0 clocks and the data capture registers are connected to the inputs rather than the outputs of the reverse shift registers:

The last case, the odd-symmetric M=2 case, combines both changes made for the even-symmetric M=2 version, as well as the last DSP48 changes needed to convert the even-symmetric filter into an odd-symmetric one:
While we have six different implementations, they are all quite similar and use exactly the same resources, just connected slightly differently. For the cases where M>4, the first two M=4 designs can be used and no further changes are required. More importantly, for M up to 16 no extra fabric resources are needed, since a single SRL16 can implement an addressable chain of up to 16 registers. For M up to 32, SRL32s would be used and so on.
These designs are a bit more complicated but they share the same features as the systolic single rate non-symmetric and symmetric FIRs. They all require N/M DSP48s for the non-symmetric FIRs, respectively N/M/2 for the symmetric cases and are efficient and scalable to any size, without loss of speed.
Back to the top: The Art of FPGA Design Season 2