


The Single Rate symmetric FIR, low latency transposed architecture
The question we need to answer now is this - for those applications that require very low latency FIRs is there a way to avoid the increase in latency proportional to the filter order that is characteristic of direct systolic implementations, both non-symmetric and even/odd-symmetric ones? We have already seen in Post 5 that the answer to this question for the non-symmetric FIR case was yes. By using the transposed FIR implementation we can build a filter with low and constant latency, independent of the order N. The price we paid for this was a loss in scalability. As the filter grows beyond 10 to 20 taps, it becomes harder and harder to achieve the maximum possible clock speed. A simple solution for this issue is the partial pipelining of the transpose FIR architecture, by inserting one register level every M taps, with M a suitable value between 10 and 20. The latency will be now proportional to N/M rather than N as is the case of the fully pipelined systolic direct structure, but the design is scalable to any size.
This worked well for the non-symmetric transpose FIR case, but is this also possible for the symmetric transpose FIR? The answer is again yes, and rather than deriving this FIR architecture from the mathematical formula we can start from the already pipelined even-symmetric direct FIR we came up with in Post 6. Here it is again for your reference, an even-symmetric FIR of order N=2*K, with K=5:
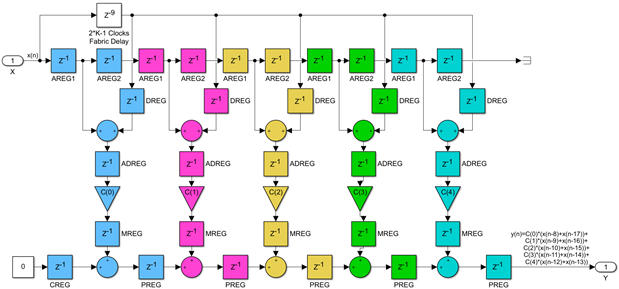
The first change we need to make is to flip the order of the coefficients, after all, this is the most important feature of the transpose implementation and why it has this name. This, of course, is now a completely different filter but if we remove the 2*K-1 fabric delay for the second data path and introduce one extra delay in the forward data path and reorganize it a bit, we get the following structure:
This is completely equivalent to the direct form implementation, but instead of a latency of K+3 clocks, which grows as the filter order N increases, the latency is now constant and equal to just 4 clocks. As a bonus, we do not even need a fabric delay anymore, but as mentioned before, we lose the scalability. As K grows the clock speed will decrease because of the high fanout net driving the D inputs of all the DSP48s. As mentioned earlier, there is a threshold, typically between 10 and 20, and if K is less than that, then there is no speed penalty.
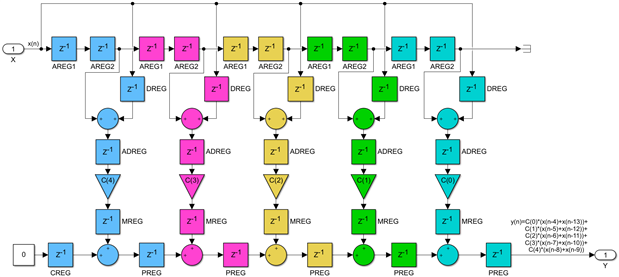
To make illustrating what needs to be done when K is larger than this threshold value M easier, we will assume M=4 from now on and consider an FIR of order N=16, so K=8. Here is this sub-optimal FIR implementation, which cannot close timing at the maximum possible clock frequency:
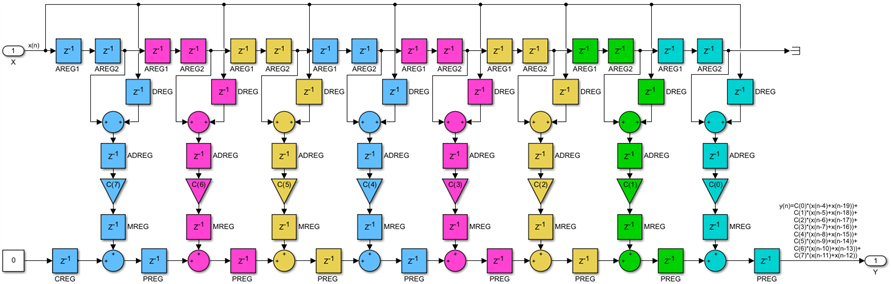
Since K=2*M, we need to break this long filter into two sections using a transversal pipeline cut and insert pipeline registers. Since the AREG chain of registers uses dedicated routing between DSP48s called the A cascade, it will not be possible to insert a fabric pipeline register there, while you can enter this delay chain from the fabric you cannot go back into FPGA fabric from it, just connect to the next DSP48. To solve this problem, we will create a parallel fabric based delay path of 2*M clocks, which is equivalent to the AREG delay chain of the first M DSP48s:
All nets crossing the pipeline cut do so in the same direction, so we just insert a one clock delay on all of them. This will not affect the design functionality, beyond increasing its latency by one clock:

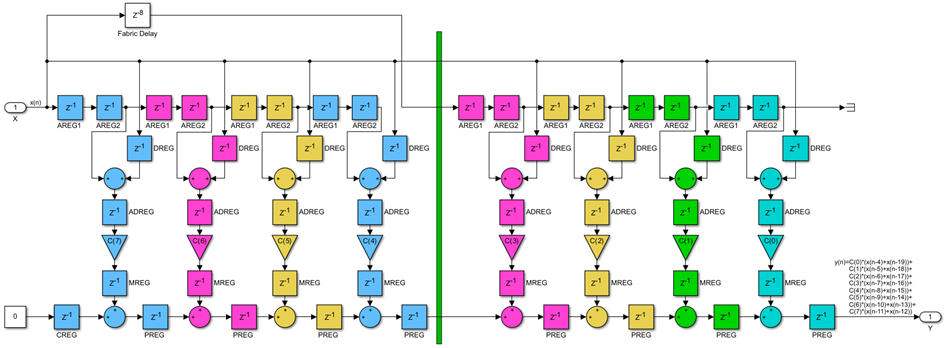
The cost of this extra pipelining is actually quite small. Of the three registers, we have added only the one in the D input path counts. The extra A input path register can be absorbed into the already existing 2*8 fabric delay, while the new post-adder chain register will become the CREG register of the first DSP48 of the second section. Both these registers are free:
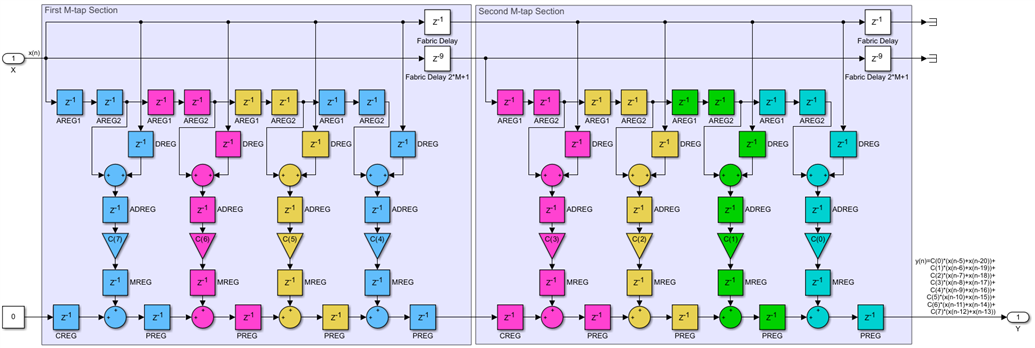
We have now a scalable design, this example has two M-tap sections, but we can increase the filter size as much as we want by cascading more of these identical sections, with no impact on the clock frequency. We can achieve this with a few extra fabric delays and a tiny increase in latency, K/M+3 clocks, instead of just 4 compared with the non-scalable transpose FIR but much better than the K+4 clocks of the direct systolic alternative.
A similar solution exists for the odd-symmetric transpose FIR case, and we can derive directly it from the even-symmetric one. For the K ≤ M case, it looks like this:
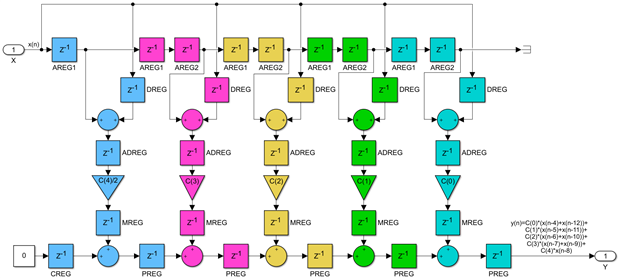
The change is minimal and affects only the first DSP48 in the chain, namely the removal of one of the two AREG registers. As was the case with the odd-symmetric direct implementations described in Post 7, this has the side effect of counting the center tap twice, which is compensated by scaling down that coefficient in half. As mentioned in that post there are better ways to address that like scaling up all the other coefficients by a factor of 2, or if that is not possible, by removing the pre-adder of the first DSP48 but for simplicity I will use this down scaling of the center tap coefficient.
Finally, when K>M we have the systolic transpose FIR implementation, with partial pipelining every M taps:
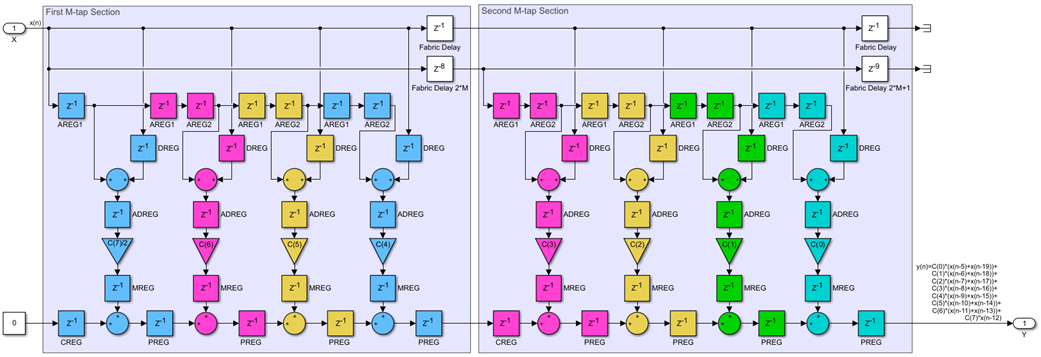
If we compare this with the even-symmetric transpose version, we can see that all sections except for the first one are identical and the filter can be scaled up to any size. The first section has a fabric delay which is one clock shorter than for the other sections, 2*M clocks instead of 2*M+1. The first DSP48 of the first section is also different, one AREG is missing and the coefficient value must be adjusted.
This concludes the review of all possible efficient implementations for a generic single rate FIR, both non-symmetric, even-symmetric and odd-symmetric. For each one of these three cases we have found that it is possible to create efficient and scalable DSP48 implementations using either a direct systolic version or a transpose non-pipelined or partially pipelined alternative. The direct implementations tend to be more efficient in terms of fabric utilization, while the transposed versions are the answer when low latency is a requirement.
In the next post we will start looking at different particular variations of this general FIR filter and we will start with the half-band FIR.
Back to the top: The Art of FPGA Design Season 2
