


I did not obtain sufficient data (both in quality and quantity) to construct an impulse (model), but I thought it would be worthwhile to review what I was trying to achieve by comparison to an impulse that I have successfully deployed using Edge Impulse.
I created and deployed a keyword spotting impulse on an Arduino Nano 33 BLE Sense board that detects the words "On" and "Off". I demonstrated that impulse in a previous post: Wio Terminal Sensor Fusion - TinyML Keyword Spotting Part 1 . I should note that I was also able to deploy and run this impulse on the Wio Terminal, but it had poor accuracy. The Wio Terminal only has an analog microphone, so I was using ADC captured data with an impulse trained using PDM microphone data. The sample rate was the same, but the spectral response may have been different.
Impulse comparison
Data acquisition
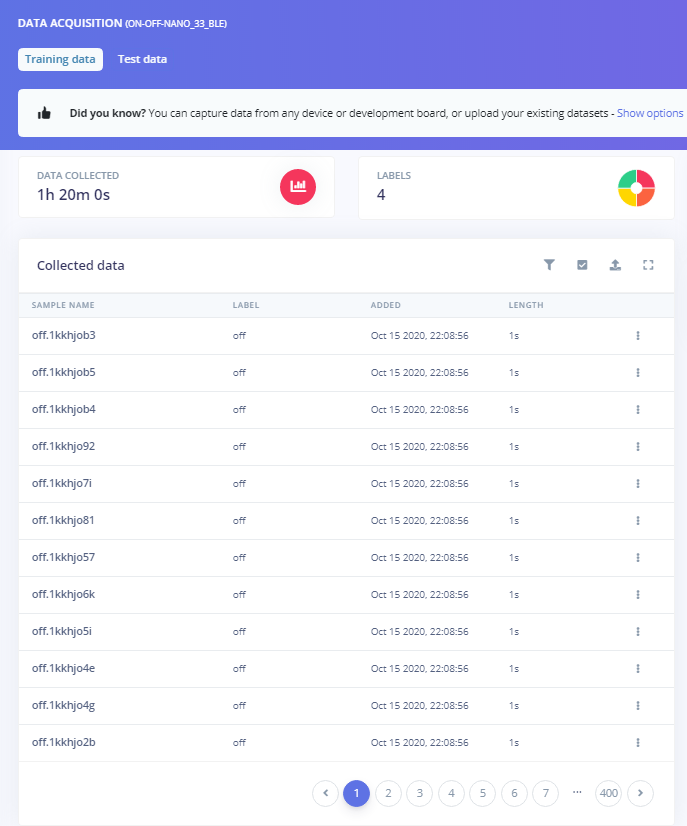
For the keyword spotting impulse, I was able to find an online database and therefore had access to a large amount of training data. I used 4 labels with 1500 one second samples per label. The samples were split with 80% for training data and 20% for test data.
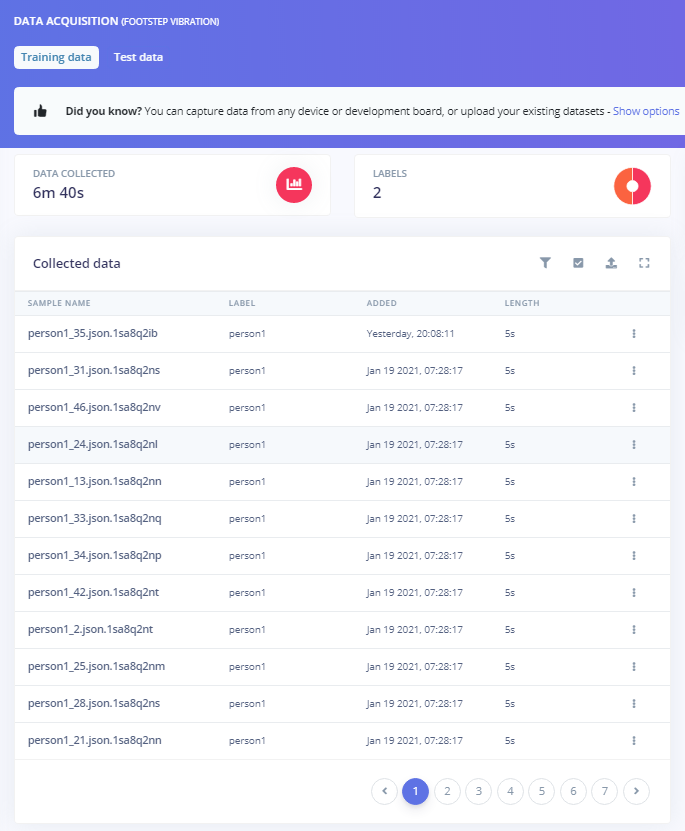
For footstep detection, I only managed to get data for 2 labels with 50 five second samples per label. I used the same 80%/20% data split.
I had planned on capturing 4 labels of data with 200-300 samples per label which I had hoped would be sufficient.
Create Impulse
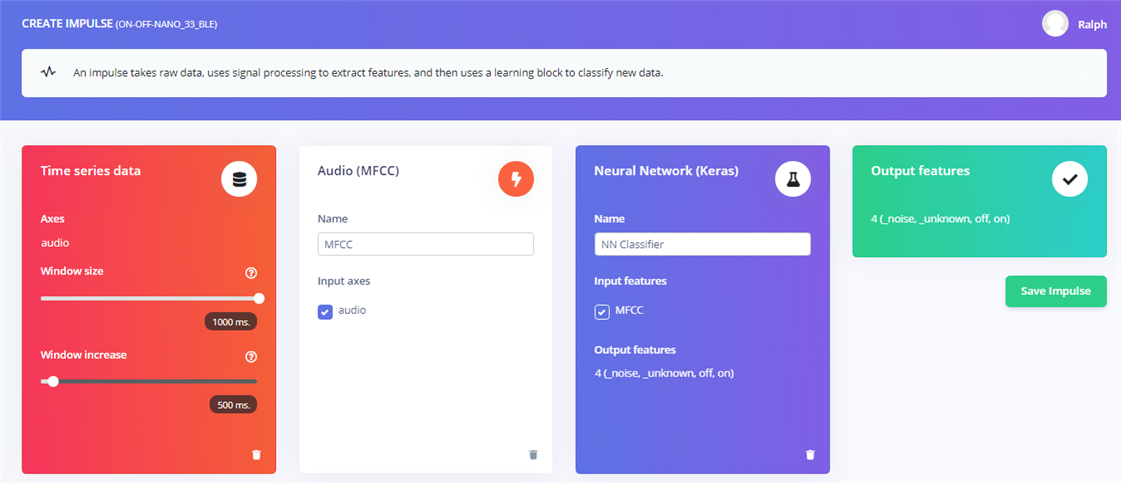
Creating an impulse requires 3 basic elements to process the data and train the impulse (model). Here is the set up for the keyword spotting.
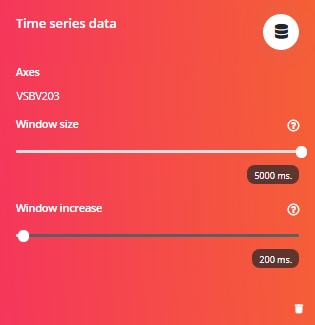
Data type
The data type for both the keyword spotting data and the vibration data is Time Series. The vibration data has a longer sample window (5 seconds vs 1 second), so window size needs to be adjusted. The window increase is the amount of overlap between sample windows. A smaller value creates more overlap and generates more data which might help with a small data set.
Processing block
The keyword spotting impulse used the MFCC (Mel Frequency Cepstral Coefficient) audio processing block to do the feature extraction from the microphone data.
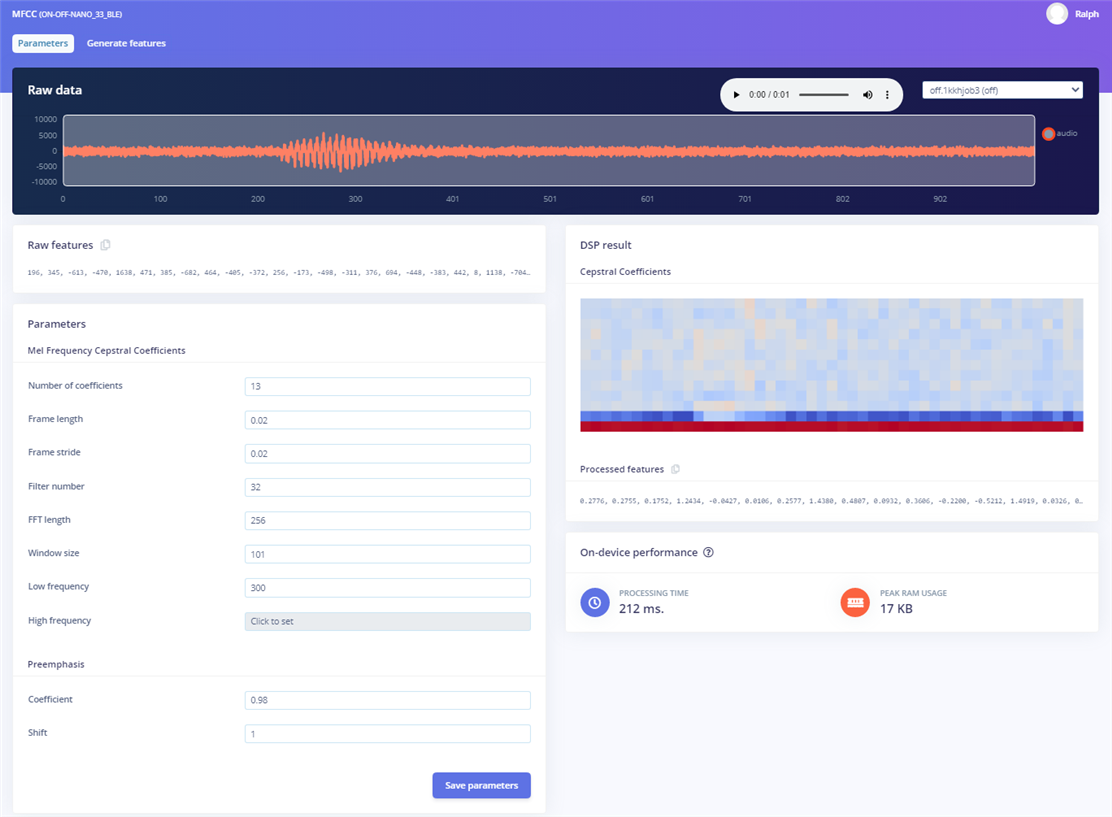
The extracted feature set.

I'm not actually sure what processing block would work best with the vibration data. Here are the standard choices that are available:
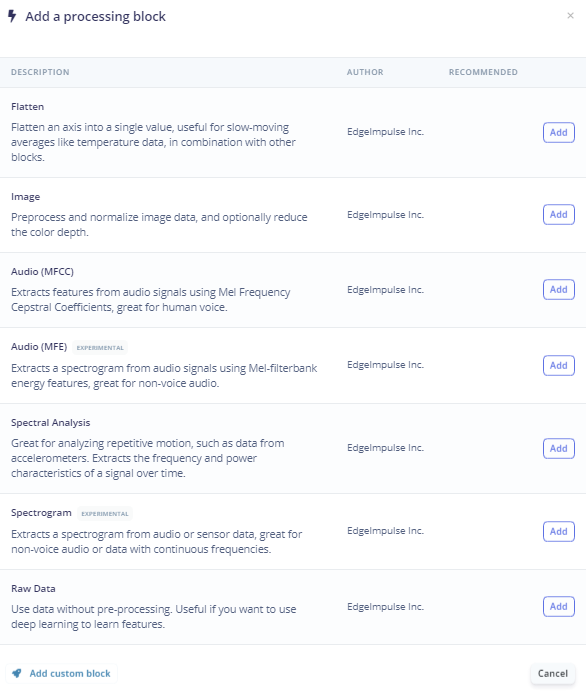
I think from the available choices that the Spectral Analysis would be the best. From reading papers about footstep detection, a good custom block might be one that could detect the spacing (time difference) between the 3 highest amplitude peaks. Of course, at this point I have no idea how to create a custom block (Edge Impulse does provide a tutorial and an example written in Python). So, I'll try Spectral Analysis. The parameters are just a guess. The Filter Cut-off frequency seems to have the most effect.

The extracted feature set.
Since in this case I'm just detecting whether there are any footsteps (idle vs person1), there is reasonable feature separation. I'm not sure how well this would do separating person1 vs person2.

Learning block
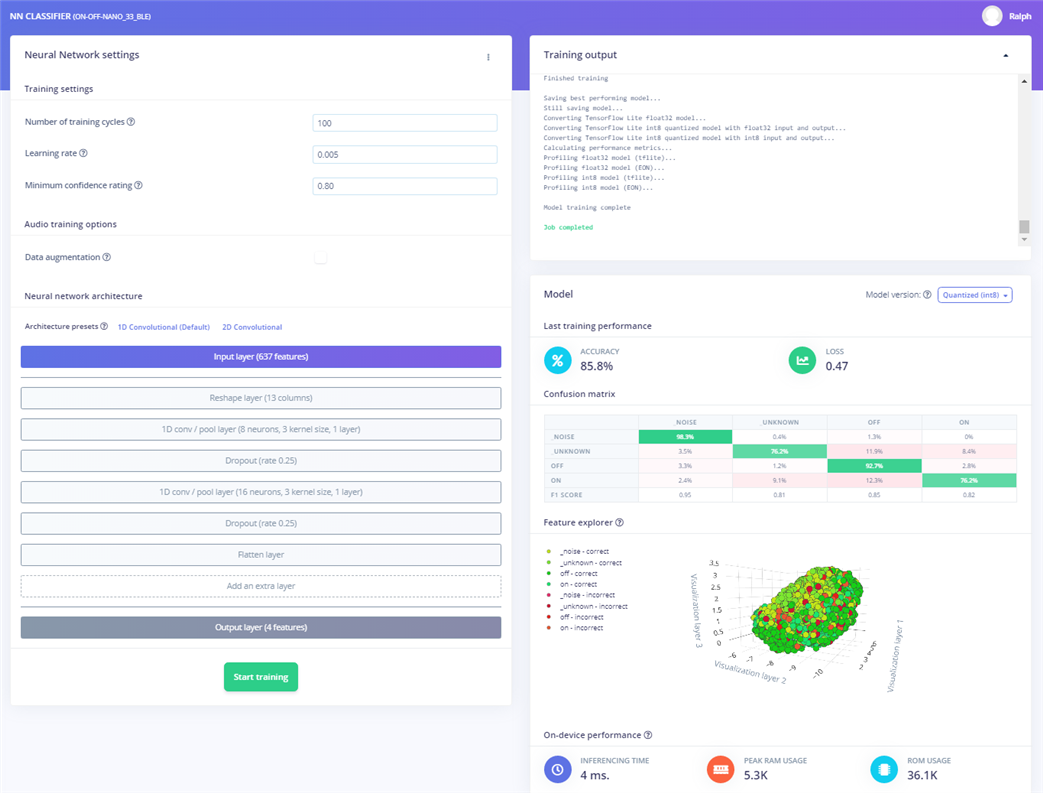
The Learning block used with keyword spotting is a Neural Network Classifier. It is shown below after training. The Confusion matrix shows reasonable accuracy (85.8%).
Here are the standard Learning block options that I could use for footstep detection:
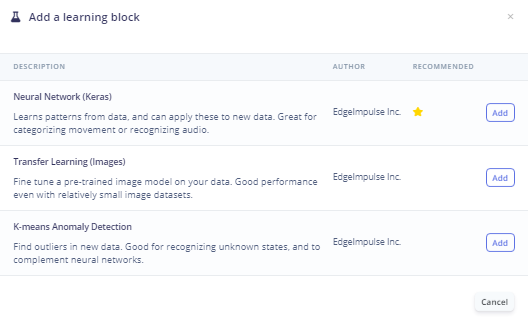
The recommended block is the same type as for the audio data, a Keras Neural Network. Most of the footstep detection papers that I have seen use the Support Vector Machine (SVM) algorithm for classification. I don't see the option to add a custom block and I haven't found a good SVM example, so I'm going to use the NN Classifier.
Here are the results after training:
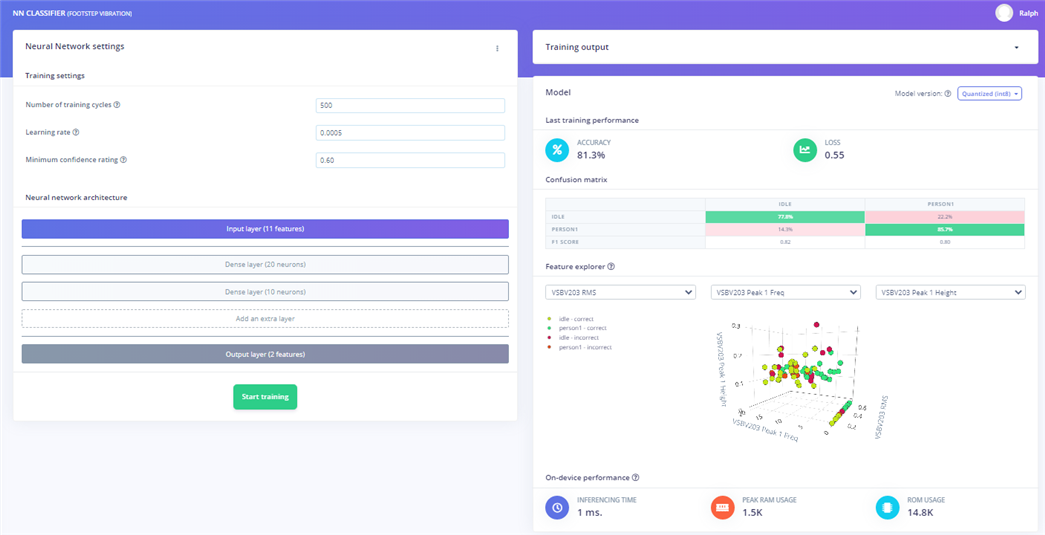
As expected, even with limited data, it has reasonable accuracy (81.3%) because there are only two classes that are reasonably distinct.
Summary
I wasn't able to achieve my goal of creating and deploying an impulse, but I gained insight into TinyML especially in context of the Edge Impulse tools.
Links to my other blogs for this challenge
Person Identification using Footstep Vibration Patterns
Vibration Sensor - Data Capture Setup
Vibration Sensor - Data Capture Program
Top Comments