


The Carry-Save Adder, two for the price of one
This post is about buying two adders but paying only for one of them.
When developing software the CPU and memory your code is running on is already paid for and there is little incentive to optimize your code to make it either smaller or faster. But as a hardware designer you literally pay for every LUT and FF in the FPGA you are using. If you could make your design smaller and faster you could do more with the same FPGA or you could use a smaller and cheaper one and if your volume production is significant this can translate into a lot of money. Fabric adders are one such good opportunity to increase the efficiency of a hardware design.
The Xilinx FPGA fabric has dedicated CARRY4/CARRY8 resources in every slice, which can be cascaded to build 2-input adders/subtracters of any size, using essentially one LUT6/FF pair per bit. If you need to add more than 2 terms you have to use more adders, in general an N-input add requires N-1 2-input adders, so N-1 LUT6/FF pairs per bit. There is however a better way to add many terms, which in general uses O(N/2) instead of O(N) LUTs per bit. Two for the price of one.
The key ingredient is a 3-input adder structure called a carry save adder. The basic idea is outlined in this diagram:
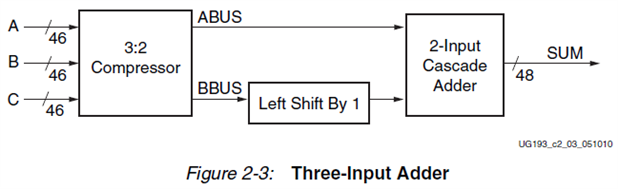
We compute first two intermediate values, a bitwise XOR of the 3 operands ABUS and a bitwise majority vote of the three operands BBUS. Then we do a normal 2-input ripple carry add of the first value and the second one shifted left by one bit and we get our 3-input addition result. If we want to avoid overflows the result has to be 2 bits larger than the operands. The trick is to observe that we can merge both the XOR3 and the 3-input majority voter logic functions in the same LUT6 that is used by the final ripple carry adder, like this:
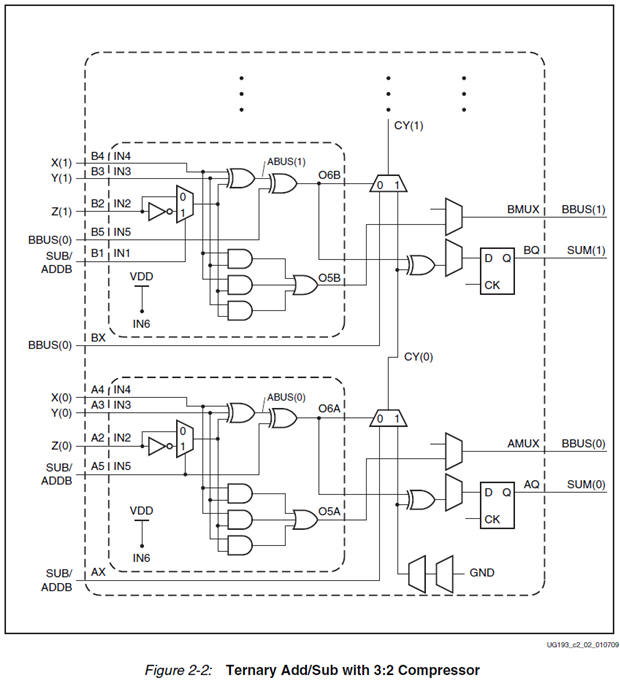
Not only can we map all these logic functions in a single LUT6_2 but we still have one LUT input left, which could be used to implement more functions, like an add/sub dynamic selection or gating one of the three operands and so on. Unfortunately we cannot have two independent dynamic add/sub selects but we can do things like O<=±A±B or even O<=C±A±B with a static add/sub selection made with generic parameters.
So how can we get this efficient 3-input adder implementation? We can code it behaviorally like this:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
entity TEST_ADD3 is
generic(PIPELINE:BOOLEAN:=TRUE;
NEGATIVE_A:BOOLEAN:=TRUE;
NEGATIVE_B:BOOLEAN:=TRUE);
port(CLK:in STD_LOGIC:='0';
A,B,C:in SIGNED(15 downto 0);
P:out SIGNED(17 downto 0)); -- O=C±A±B
end TEST_ADD3;
architecture FAST of TEST_ADD3 is
begin -- combinatorial 3-input adder
i0:if not PIPELINE generate -- we must sign extend A, B and C by 2 MSBs to account for the 2-bit growth when adding 3 operands
signal RA:SIGNED(A'high+2 downto A'low);
signal RB:SIGNED(B'high+2 downto B'low);
signal RC:SIGNED(C'high+2 downto C'low);
begin – sign extend A, B and C by 2 MSBs
RA<=RESIZE(A,RA'length);
RB<=RESIZE(B,RB'length);
RC<=RESIZE(C,RC'length);
P<=RESIZE(RC-RA-RB,P'length) when NEGATIVE_A and NEGATIVE_B else
RESIZE(RC+RA-RB,P'length) when NEGATIVE_A and not NEGATIVE_B else
RESIZE(RC-RA+RB,P'length) when not NEGATIVE_A and NEGATIVE_B else
RESIZE(RC+RA+RB,P'length); -- when not NEGATIVE_A and not NEGATIVE_B
end generate;
-- registered 3-input adder
i1:if PIPELINE generate -- we must sign extend A, B and C by 2 MSBs to account for the 2-bit growth when adding 3 operands
signal RA:SIGNED(A'high+2 downto A'low):=(others=>'0');
signal RB:SIGNED(B'high+2 downto B'low):=(others=>'0');
signal RC:SIGNED(C'high+2 downto C'low):=(others=>'0');
begin
-- register inputs to measure fMAX
process(CLK)
begin
if rising_edge(CLK) then
RA<=RESIZE(A,RA'length);
RB<=RESIZE(B,RB'length);
RC<=RESIZE(C,RC'length);
end if;
end process;
-- this is the actual 3-input adder
process(CLK)
begin
if rising_edge(CLK) then
if NEGATIVE_A then
if NEGATIVE_B then
P<=RESIZE(RC-RA-RB,P'length);
else
P<=RESIZE(RC-RA+RB,P'length);
end if;
else
if NEGATIVE_B then
P<=RESIZE(RC+RA-RB,P'length);
else
P<=RESIZE(RC+RA+RB,P'length);
end if;
end if;
end if;
end process;
end generate;
end FAST;
This is an example for integer numbers so the SIGNED type is used but the fixed point version is very similar. However, while we get indeed a single chain of CARRY8s instead of two, the mapping of two LUT3s into a single LUT6_2 is inconsistent and in the end we do not get the promised 50% discount. The 3-input adder is virtually the only case where simple behavioral coding for adders and subtracters is not the optimal choice and we have to revert to primitive instantiations. If we go this path it is worth creating a generic and reusable module. For example, the three input ports should be unconstrained fixed precision types, not necessarily the same range and the output should also be an unconstrained and arbitrary range fixed point type. If we reuse the Types_pkg.vhd package file we talked about in an earlier post, which introduces the SFIXED arbitrary fixed point precision type and associated functions we can write a generic 3-input adder/subtracter like this:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all;
library UNISIM;
use UNISIM.VComponents.all;
entity CSA3 is
generic(PIPELINE:BOOLEAN:=TRUE;
NEGATIVE_A:BOOLEAN:=FALSE;
NEGATIVE_B:BOOLEAN:=FALSE;
EXTRA_MSBs:INTEGER:=2);
port(CLK:in STD_LOGIC:='0';
A,B,C:in SFIXED; -- if SFIXED, A, B, C and P can be any size
P:out SFIXED); -- O=C±A±B
end CSA3;
architecture FAST of CSA3 is
constant SH:INTEGER:=MAX(A'high,B'high,C'high)+EXTRA_MSBs;
constant SM:INTEGER:=work.TYPES_PKG.MED(A'low,B'low,C'low);
constant SL:INTEGER:=work.TYPES_PKG.MIN(A'low,B'low,C'low);
signal SA,SB,SC:SFIXED(SH downto SM);
signal S:SFIXED(SH downto SL);
signal O5:SIGNED(SH-SM+1 downto 0);
signal O6:SIGNED(SH-SM downto 0);
signal CY:STD_LOGIC_VECTOR((SH-SM+1+7)/8*8 downto 0);
signal SI,DI,O:STD_LOGIC_VECTOR((SH-SM+1+7)/8*8-1 downto 0);
begin -- resize all three operands to a common range SH downto SM
SA<=RESIZE(A,SA);
SB<=RESIZE(B,SB);
SC<=RESIZE(C,SC);
-- if subtracting, the corresponding carry input is set high
O5(0)<='1' when NEGATIVE_A else '0';
CY(0)<='1' when NEGATIVE_B else '0';
-- generate loop to instantiate a LUT6_2 for every bit
lk:for K in SM to SH generate
constant I0:BIT_VECTOR(63 downto 0):=X"AAAAAAAAAAAAAAAA";
constant I1:BIT_VECTOR(63 downto 0):=X"CCCCCCCCCCCCCCCC";
constant I2:BIT_VECTOR(63 downto 0):=X"F0F0F0F0F0F0F0F0" xor (63 downto 0=>BIT'val(BOOLEAN'pos(NEGATIVE_B))); -- this inverts B if NEGATIVE_B
constant I3:BIT_VECTOR(63 downto 0):=X"FF00FF00FF00FF00" xor (63 downto 0=>BIT'val(BOOLEAN'pos(NEGATIVE_A))); -- this inverts A if NEGATIVE_A
constant I4:BIT_VECTOR(63 downto 0):=X"FFFF0000FFFF0000";
constant I5:BIT_VECTOR(63 downto 0):=X"FFFFFFFF00000000";
begin
l6:LUT6_2 generic map(INIT=>(I5 and (I1 xor I2 xor I3 xor I4)) or (not I5 and ((I2 and I3) or (I3 and I1) or (I1 and I2))))
port map(I0=>'0',I1=>SC(K),I2=>SB(K),I3=>SA(K),I4=>O5(K-SM),I5=>'1',O5=>O5(K+1-SM),O6=>O6(K-SM));
end generate;
-- generate loop to instantiate a CARRY8 for every 8 bits
SI<=STD_LOGIC_VECTOR(RESIZE(O6,SI'length));
DI<=STD_LOGIC_VECTOR(RESIZE(O5,DI'length));
lj:for J in 0 to (SH-SM)/8 generate
begin
c8:CARRY8 generic map(CARRY_TYPE=>"SINGLE_CY8") -- 8-bit or dual 4-bit carry (DUAL_CY4, SINGLE_CY8)
port map(CI=>CY(8*J), -- 1-bit input: Lower Carry-In
CI_TOP=>'0', -- 1-bit input: Upper Carry-In
DI=>DI(8*J+7 downto 8*J), -- 8-bit input: Carry-MUX data in
S=>SI(8*J+7 downto 8*J), -- 8-bit input: Carry-mux select
CO=>CY(8*J+8 downto 8*J+1), -- 8-bit output: Carry-out
O=>O(8*J+7 downto 8*J)); -- 8-bit output: Carry chain XOR data out
end generate;
-- the upper portion of the result (SH downto SM) is given by the adder
ll:for L in SM to SH generate
S(L)<=O(L-SM);
end generate;
-- the lower portion of the result (SM-1 downto SL) is given by the operand with the smallest 'low
ia:if (A'low<B'low) and (A'low<C'low) generate
S(SM-1 downto SL)<=A(SM-1 downto SL);
end generate;
ib:if (B'low<C'low) and (B'low<A'low) generate
S(SM-1 downto SL)<=B(SM-1 downto SL);
end generate;
ic:if (C'low<A'low) and (C'low<B'low) generate
S(SM-1 downto SL)<=C(SM-1 downto SL);
end generate;
-- if combinatorial adder just resize the sum S to match the P output range
i0:if not PIPELINE generate
P<=RESIZE(S,P'high,P'low);
end generate;
-- if registered adder resize the sum S to match the P output range and register it
i1:if PIPELINE generate
signal iP:SFIXED(P'range):=(others=>'0');
begin
process(CLK)
begin
if rising_edge(CLK) then
iP<=RESIZE(S,P'high,P'low);
end if;
end process;
P<=iP;
end generate;
end FAST;
This is a more involved design because we want to support arbitrary fixed point numbers not necessarily of identical range. The three inputs and the outputs can have different ranges and the design will align the binary points. The operands are resized to a multiple of 8 bits and LUT6es and CARRY8 primitives are instantiated. The result is resized to the range of the output port by zero padding or sign extending respectively truncating bits as needed. This generic 3-input adder could be instantiated in a design like this:
library IEEE;
use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD.all;
use work.TYPES_PKG.all;
entity TEST_CSA3 is
generic(PIPELINE:BOOLEAN:=TRUE;
NEGATIVE_A:BOOLEAN:=TRUE;
NEGATIVE_B:BOOLEAN:=TRUE);
port(CLK:in STD_LOGIC:='0';
A,B,C:in SFIXED(15 downto 0);
P:out SFIXED(17 downto 0)); -- O=C±A±B
end TEST_CSA3;
architecture FAST of TEST_CSA3 is
signal RA:SFIXED(A'range):=(others=>'0');
signal RB:SFIXED(B'range):=(others=>'0');
signal RC:SFIXED(C'range):=(others=>'0');
begin
-- register inputs to measure fMAX
process(CLK)
begin
if rising_edge(CLK) then
RA<=A;
RB<=B;
RC<=C;
end if;
end process;
-- generic 3-input carry save adder
u1:entity work.CSA3 generic map(PIPELINE=>PIPELINE,
NEGATIVE_A=>NEGATIVE_A,
NEGATIVE_B=>NEGATIVE_B)
port map(CLK=>CLK,
A=>RA,
B=>RB,
C=>RC,
P=>P);
end FAST;
The design now uses the expected 1 LUT6 per bit and can still reach speeds of over 800MHz. With this coding style we can indeed get two adders for the price of one.
In the next post we will see a few example designs where using this generic 3-input adder would make sense.
Back to the top: The Art of FPGA Design
-

kraja_z
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Comment-

kraja_z
-
Cancel
-
Vote Up
0
Vote Down
-
-
Sign in to reply
-
More
-
Cancel
Children