


Artificial Intelligence is one of the hottest topics across many industry sectors, from autonomous driving to IOT / IIOT, robotics, and big data analysis. Indeed, the management consultants McKinsey & Company estimate the market for AI will grow between 15 and 25% a year, and is projected to be worth $130 billion by 2025. 
Why is AI experiencing such rapid growth? One of the main reasons is that AI provides systems with the ability to do tasks which have been traditionally achieved by humans. However, when an AI solution is implemented, it is typically significantly faster and has greater accuracy. Most implementations of AI are focused upon one task, or a set of tightly constrained tasks, for instance medical diagnosis or autonomous vehicle operation.
What is the difference between Artificial Intelligence and Machine Learning?
What AI does not define is how the intelligence is implemented. One approach would be to follow a traditional software engineering approach where functionality is specifically coded. However, for complex tasks this could take significant time and becomes inefficient.
This is where Machine Learning comes in. Machine Learning is a subset of AI, where in place of explicitly implementing the behaviour required, the ML algorithm is trained with a dataset to create an analytical model which enables the prediction within an acceptable tolerance. In ML implementations, this algorithm is based upon an Artificial Neural Network.
What are Artificial Neural Networks?
Artificial Neural Networks is a term used to cover a variety of neural network configurations. However, at the highest level, an Artificial Neural Network can be modelled on the human cerebral cortex in that each neuron receives an input, processes it, and communicates the processed signal to another neuron.
Therefore, Artificial Neural Networks typically consist of multiple layers which can be described as containing an input layer, internal layer(s), and an output layer.
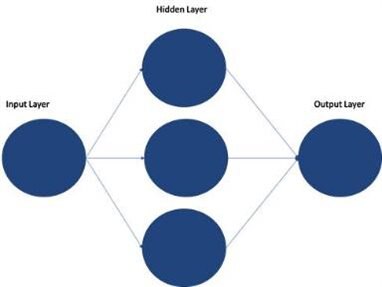
Figure 1: Simple Neural Network
There are several classes of Artificial Neural networks. Those which pass the output of one layer to another without feedback are called Feedforward Neural Networks (FNN), while those which contain feedback, for example an Elman network, are called Recurrent Neural Networks (RNN).
One very commonly used term in machine learning is Deep Neural Networks (DNN). These are neural networks which have several hidden layers enabling a more complex machine learning task to be implemented.
An increasingly popular Machine Learning application is implementing Convolutional Neural Networks. Convolutional Neural Networks are used when the input is two dimensional, as is the case for embedded vision applications.
To implement a CNN, there exist several different structures which have evolved over time from AlexNet to GoogleNet, SDD and FCN. However, they are formed of the same basic functional blocks, although with different parameterisations. These stages are Convolution, Rectified Linear Unit (reLU), Max Pooling, and Fully Connected. When we train a CNN, we define parameters for the Convolution (filter weights) and Fully Connected layers (weights and bias), while the Max Pool and reLU elements require no weights or biases, although Max Pool requires parameterisation to define the size of the filter kernel and the stride.
How do we implement a machine learning solution?
To develop machine learning applications, there is a range of open source and free software we can use, from Caffe to Tensorflow and Torch/PyToch. These software tools allow us to define, train, and implement our machine learning application, without the need to start from scratch.
For edge-based applications, the challenges include power efficiency, security, real-time response, and determinism along with high performance. The implementation of floating point weights and biases results in a solution which is not optimal in performance, determinism or power dissipation. A class of neural networks called Binary Neural Networks is increasingly popular for edge-based deployments. These applications use binary variables for weights and biases.
Of course, before we can deploy a neural network we first need to train the network to determine the value of the weights and biases used within each layer. Training introduces an additional layer to the network, which implements a loss function. This loss function enables the training algorithm to determine if the network correctly identified the input.
When we are developing CNNs we require large image sets to train the network. Two potential sources of such images sets are www.image-net.org and http://bdd-data.berkeley.edu.
To apply and work with the large data/image sets and calculate the biases and weights as quickly and as efficiently as possible, large farms of Graphical Processing Units (GPUs) are often used.
GPU farms are ideal for training, as the goal of training is to generate the weights and biases within the minimal time frame. Therefore, power efficiency, real-time response, and determinism for each input is not as critical as it is within the actual deployment.
Therefore, GPU farms provide the most efficient mechanism for determining the neural network weights and biases.
What are the differences between Edge and Cloud Deployments?
For deployment of a machine learning application the technology depends upon its use cases and requirements.
Edge-based implementations of machine learning are used when connectivity to the cloud cannot always be guaranteed and the application requires a critical response time in its decision loop, for example an autonomous vehicle. Edge based applications also bring requirements for any-to-any interfacing, security, and power efficiency along with the need for high performance.
Designers of edge-based applications are increasingly using heterogeneous System on Chips like the Xilinx Zynq-7000 SoC and Zynq UltraScale+ MPSoC which combine Programmable Logic (PL) fabric with high performance ARM cores in the Processing System (PS). This combination of PL and PS allows the creation of a machine learning inference engine which demonstrates improved determinism and response time, is very flexible for future modification, and offers a power efficient and secure solution.
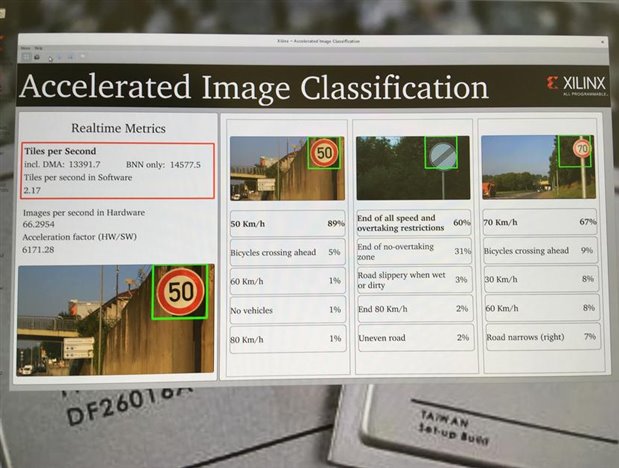
Figure 2: Road Sign detection, Binary Neural Network running on an Ultra 96 (Zynq MPSoC)
When it comes to cloud-based Machine learning deployments, the application is still compute-intensive and could still benefit from acceleration. Cloud-based machine learning can work with large volumes and a variety of data with large storage requirements. To accelerate machine learning applications in the cloud, hyperscale cloud companies such as Amazon Web Services and Baidu have introduced high performance FPGA devices into their server architecture, to enable acceleration.
There is no doubt that AI and ML will continue grow and be a major component of many systems for the foreseeable future. The proverbial iron is hot. Why not download one of the free software development tools and start working on your own AI/ML application?